Uložené procedury v T-SQL - vytváření, modifikace, mazání. Jak správně zapisovat uložené procedury v SQL Server Uložené procedury v databázi
Prohlášení o postupu
VYTVOŘIT POSTUP [({IN|OUT|INOUT} [,…])]
[DYNAMICKÁ SADA VÝSLEDKŮ ]
ZAČÍT [ATOMOVÝ]
KONEC
Klíčová slova
. IN (Input) – vstupní parametr
. OUT (Output) – výstupní parametr
. INOUT – vstup a výstup, stejně jako pole (bez parametrů)
. DYNAMIC RESULT SET označuje, že procedura může otevřít zadaný počet kurzorů, které zůstanou otevřené po návratu procedury
Poznámky
Nedoporučuje se používat mnoho parametrů v uložených procedurách (především velká čísla a znakové řetězce) kvůli přetížení sítě a zásobníku. V praxi se stávající dialekty Transact-SQL, PL/SQL a Informix výrazně liší od standardu, a to jak v deklaraci a použití parametrů, deklarací proměnných, tak ve volání podprogramů. Společnost Microsoft doporučuje k odhadu velikosti mezipaměti uložené procedury použít následující přiblížení:
=(maximální počet souběžných uživatelů)*(velikost největšího exekučního plánu)*1,25. Určení velikosti prováděcího plánu ve stránkách lze provést pomocí příkazu: DBCC MEMUSAGE.
Volání procedury
V mnoha existujících DBMS se uložené procedury volají pomocí operátoru:
PROVEĎTE POSTUP [(][)]
Poznámka: Volání uložených procedur lze provádět z aplikace, jiné uložené procedury nebo interaktivně.
Příklad deklarace procedury
CREATE PROCEDURE Proc1 AS //deklarujte proceduru
DECLARE Cur1 CURSOR FOR SELECT SName, City FROM SalesPeople WHERE Rating>200 //deklarujte kurzor
OPEN Cur1 //otevření kurzoru
FETCH NEXT FROM Cur1 //přečtení dat z kurzoru
WHILE @@Fetch_Status=0
ZAČÍT
NAČÍST DALŠÍ Z Cur1
KONEC
CLOSE Cur1 //zavření kurzoru
DEALOCATE Cur1
EXECUTE Proc1 //spusťte proceduru
Polymorfismus
Dva podprogramy se stejným názvem lze vytvořit ve stejném schématu, pokud se parametry těchto dvou podprogramů od sebe dostatečně liší, aby je bylo možné rozlišit. Aby bylo možné rozlišit mezi dvěma rutinami se stejným názvem ve stejném schématu, každá dostane alternativní a jedinečný název (specifický název). Takový název může být explicitně specifikován při definování podprogramu. Při volání podprogramů s několika stejnými názvy se určení požadovaného podprogramu provádí v několika krocích:
. Na začátku jsou definovány všechny procedury se zadaným názvem, a pokud žádné nejsou, pak všechny funkce s daným názvem.
. Pro další analýzu jsou zachovány pouze ty podprogramy, pro které má uživatel oprávnění EXECUTE.
. Pro ně jsou vybrány ty, jejichž počet parametrů odpovídá počtu argumentů volání. Kontrolují se zadané datové typy parametrů a jejich pozice.
. Pokud zbývá více než jeden podprogram, vybere se ten, jehož kvalifikační název je kratší.
V praxi je v Oracle polymorfismus podporován pro funkce deklarované pouze v balíčku, DB@ - v různých schématech a v Sybase a MS SQL Serveru je zakázáno přetěžování.
Mazání a změna postupů
Chcete-li odstranit proceduru, použijte operátor:
Chcete-li změnit postup, použijte operátor:
ZMĚNIT POSTUP [([{IN|OUT|INOUT}])]
ZAČÍT [ATOMOVÝ]
KONEC
Oprávnění provádět procedury
GRANT PROVÁDĚT DÁL NA |VEŘEJNOST [S MOŽNOSTÍ GRANTU]
Systémové postupy
Mnoho DBMS (včetně SQL Server) má specifickou sadu vestavěných systémových uložených procedur, které můžete použít pro své vlastní účely.
Typy uložených procedur
SQL Server má několik typů uložené procedury.
- Systém uložené procedury určené k provádění různých administrativních akcí. Téměř všechny činnosti správy serveru jsou prováděny s jejich pomocí. Dá se říci, že systémové uložené procedury jsou rozhraním, které zajišťuje práci se systémovými tabulkami, což v konečném důsledku spočívá ve změně, přidávání, mazání a načítání dat ze systémových tabulek uživatelských i systémových databází. Systém uložené procedury mají předponu sp_, jsou uloženy v systémové databázi a lze je volat v kontextu jakékoli jiné databáze.
- Zvyk uložené procedury provádět určité akce. Uložené procedury– plnohodnotný databázový objekt. V důsledku toho každý uložené procedury se nachází ve specifické databázi, kde se spouští.
- Dočasný uložené procedury existují pouze chvíli, poté jsou automaticky zničeny serverem. Dělí se na lokální a globální. Místní dočasné uložené procedury lze volat pouze ze spojení, ve kterém byly vytvořeny. Při vytváření takové procedury jí musíte dát název, který začíná jedním znakem #. Jako všechny dočasné předměty, uložené procedury tohoto typu jsou automaticky odstraněny, když se uživatel odpojí nebo restartuje nebo zastaví server. Globální dočasné uložené procedury jsou dostupné pro všechna připojení ze serveru, který má stejný postup. Chcete-li jej definovat, stačí jej pojmenovat začínající znaky ## . Tyto procedury jsou odstraněny při restartování nebo zastavení serveru nebo po uzavření připojení v kontextu, ve kterém byly vytvořeny.
Vytváření, úpravy a odstraňování uložených procedur
Stvoření uložené procedury zahrnuje řešení následujících problémů:
- určení typu vytvořeného uložené procedury: dočasné nebo vlastní. Navíc si můžete vytvořit svůj vlastní systém uložené procedury, dejte mu název s předponou sp_ a umístěte jej do systémové databáze. Tento postup bude dostupný v kontextu jakékoli lokální databáze serveru;
- plánování přístupových práv. Při tvorbě uložené procedury je třeba vzít v úvahu, že bude mít stejná přístupová práva k databázovým objektům jako uživatel, který jej vytvořil;
- definice parametry uložené procedury. Podobně jako postupy obsažené ve většině programovacích jazyků, uložené procedury může mít vstupní a výstupní parametry;
- vývoj kódu uložené procedury. Kód procedury může obsahovat sekvenci libovolných příkazů SQL, včetně volání jiných uložené procedury.
Vytvoření nového a změna stávajícího uložené procedury provede se pomocí následujícího příkazu:
<определение_процедуры>::= (CREATE | ALTER ) název_procedury [;číslo] [(@název_parametru datový_typ ) [=výchozí] ][,...n] AS sql_operátor [...n]
Podívejme se na parametry tohoto příkazu.
Pomocí předpon sp_ , # , ## lze vytvořenou proceduru definovat jako systémovou nebo dočasnou. Jak je patrné ze syntaxe příkazu, není dovoleno uvádět jméno vlastníka, který bude vlastnit vytvořenou proceduru, a také název databáze, kde se má nacházet. Tedy za účelem umístění vytvořeného uložené procedury v konkrétní databázi musíte zadat příkaz CREATE PROCEDURE v kontextu této databáze. Při otáčení od těla uložené procedury zkrácené názvy lze použít pro objekty stejné databáze, tj. bez zadání názvu databáze. Pokud potřebujete přistupovat k objektům umístěným v jiných databázích, je zadání názvu databáze povinné.
Číslo v názvu je identifikační číslo uložené procedury, který jej jednoznačně identifikuje ve skupině procedur. Pro usnadnění řízení jsou postupy logicky stejného typu uložené procedury lze seskupit tak, že jim dáte stejný název, ale různá identifikační čísla.
K přenosu vstupních a výstupních dat ve vytvořeném uložené procedury lze použít parametry, jejichž názvy, stejně jako názvy lokálních proměnných, musí začínat znakem @. Jeden uložené procedury Můžete zadat více parametrů oddělených čárkami. Tělo procedury by nemělo používat lokální proměnné, jejichž názvy se shodují s názvy parametrů této procedury.
Chcete-li určit datový typ, který odpovídá parametr uložené procedury, jsou vhodné jakékoli datové typy SQL, včetně uživatelsky definovaných. Datový typ CURSOR však lze použít pouze jako výstupní parametr uložené procedury, tj. zadáním klíčového slova OUTPUT.
Přítomnost klíčového slova OUTPUT znamená, že odpovídající parametr má vracet data uložené procedury. To však neznamená, že parametr není vhodný pro předávání hodnot uložené procedury. Zadáním klíčového slova OUTPUT dáváte serveru pokyn k ukončení uložené procedury přiřaďte aktuální hodnotu parametru lokální proměnné, která byla zadána při volání procedury jako hodnota parametru. Všimněte si, že při zadávání klíčového slova OUTPUT lze hodnotu odpovídajícího parametru při volání procedury nastavit pouze pomocí lokální proměnné. Jakékoli výrazy nebo konstanty, které jsou povoleny pro běžné parametry, nejsou povoleny.
Klíčové slovo VARYING se používá ve spojení s
Uložené procedury
Předmětem této kapitoly je jeden z nejvýkonnějších nástrojů nabízených vývojářům databázových aplikací InterBase pro implementaci obchodní logiky Uložené procedury (anglicky, stoied proceduies) umožňují implementovat významnou část aplikační logiky na úrovni databáze a tím zvýšit. Výkon celé aplikace, centralizace zpracování dat a snížení množství kódu potřebného k dokončení zadaných úkolů Téměř žádná poměrně složitá databázová aplikace se neobejde bez použití uložených procedur.
Kromě těchto dobře známých výhod používání uložených procedur, společných pro většinu relačních DBMS, mohou uložené procedury InterBase fungovat jako téměř kompletní datové sady, což umožňuje, aby výsledky, které vrací, byly použity v běžných SQL dotazech.
Začínající vývojáři si často představují uložené procedury jednoduše jako sadu specifických SQL dotazů, které dělají něco uvnitř databáze, a panuje názor, že práce s uloženými procedurami je mnohem obtížnější než implementace stejné funkce v klientské aplikaci ve vysoce jazyk na úrovni
Co jsou tedy uložené procedury v InterBase?
Uložená procedura (SP) je součástí databázových metadat, což je podprogram zkompilovaný do vnitřní reprezentace InterBase, napsaný ve speciálním jazyce, jehož kompilátor je zabudován do jádra serveru InteiBase.
Uloženou proceduru lze volat z klientských aplikací, ze spouštěčů az jiných uložených procedur. Uložená procedura běží uvnitř procesu serveru a může manipulovat s daty v databázi a také vracet výsledky svého spuštění klientovi, který ji zavolal (tj. trigger, HP, aplikace)
Základem výkonných schopností, které jsou HP vlastní, je procedurální programovací jazyk, který zahrnuje jak modifikované příkazy běžného SQL, jako INSERT, UPDATE a SELECT, tak nástroje pro organizaci větví a smyček (IF, WHILE), stejně jako nástroje pro řešení chyb a výjimečné situace Jazyk uložených procedur umožňuje implementovat složité algoritmy pro práci s daty a díky zaměření na práci s relačními daty je HP mnohem kompaktnější než podobné procedury v tradičních jazycích.
Je třeba poznamenat, že pro spouštěče se používá stejný programovací jazyk, s výjimkou řady funkcí a omezení. Rozdíly mezi podmnožinou jazyka používaného ve triggerech a jazykem HP jsou podrobně diskutovány v kapitole „Triggers“ (část 1).
Příklad jednoduché uložené procedury
Je čas vytvořit svou první uloženou proceduru a použít ji jako příklad, abyste se naučili proces vytváření uložených procedur. Nejprve bychom si ale měli říci pár slov o tom, jak pracovat s uloženými procedurami. Faktem je, že HP za svou pověst obskurního a nepohodlného nástroje vděčí extrémně špatným standardním nástrojům pro vývoj a ladění uložených procedur. Dokumentace InterBase doporučuje vytvářet procedury pomocí souborů skriptů SQL obsahujících text HP, které jsou dodávány jako vstup do interpretu isql, a tím vytvářet a upravovat HP If v tomto skriptu SQL, ve fázi kompilace textu procedury v BLR (asi BLR, viz kapitola "Struktura databáze InterBase" (část 4)), pokud dojde k chybě, isql zobrazí zprávu o tom, na kterém řádku souboru skriptu SQL k této chybě došlo. Opravte chybu a udělejte to znovu. Vůbec se nemluví o ladění v moderním slova smyslu, tedy o trasování provádění s možností zobrazit mezihodnoty proměnných. Je zřejmé, že tento přístup nepřispívá k růstu atraktivity uložených procedur v očích vývojáře
Ovšem kromě standardního minimalistického přístupu k vývoji HP<_\ществ\ют также
инструменты сторонних разработчиков, которые делают работу с хранимыми
процедурами весьма удобной Большинство универсальных продуктов для работы с
InterBase, перечисленных в приложении "Инструменты администратора и разработчика
InterBase", предоставляют удобный инструментарий для работы с ХП. Мы рекомендуем
обязательно воспользоваться одним из этих инструментов для работы с хранимыми
процедурами и изложение материала будем вести в предположении, что у вас имеется
удобный GUI-инструмент, избавляющий от написания традиционных SQL-скриптов
Syntaxe uložených procedur je popsána takto:
CREATE PROCEDURE name
[ (param datový typ [, param datový typ ...]) ]
)]
TAK JAKO
< procedure_body> =
[
<
block>
< vanable_declaration_list>
=
DECLARE VARIABLE var datový typ;
ZAČÍT
< compound_statement>
[< compound_statement> ...]
KONEC
< compound_statement> =
(
Působí poměrně objemně a může být i těžkopádný, ale ve skutečnosti je vše velmi jednoduché, abychom si postupně osvojili syntaxi, podívejme se na postupně složitější příklady.
Zde je příklad velmi jednoduché uložené procedury, která vezme dvě čísla jako vstup, přidá je a vrátí výsledek:
CREATE PROCEDURE SP_Add(first_arg DOUBLE PRECISION,
second_arg DVOJNÁSOBNÁ PŘESNOST)
VRÁCENÍ (výsledek DVOJNÁSOBNÁ PŘESNOST)
TAK JAKO
ZAČÍT
Vysledek=prvni_argument+druhy_argument;
POZASTAVIT;
KONEC
Jak vidíte, vše je jednoduché: po příkazu CREATE PROCEDURE je uvedeno jméno nově vytvořené procedury (které musí být v rámci databáze jedinečné) - v tomto případě SP_Add, poté jsou vstupní parametry HP - first_arg a second_arg - uvedené v závorkách, oddělené čárkami s uvedením jejich typů.
Seznam vstupních parametrů je volitelnou součástí příkazu CREATE PROCEDURE - jsou případy, kdy procedura obdrží všechna data pro svou práci prostřednictvím dotazů do tabulek uvnitř těla procedury.
Uložené procedury používají jakékoli skalární datové typy InteiBase Neumožňuje použití polí a uživatelsky definovaných typů - domén
Dále následuje klíčové slovo RETURNS, za nímž jsou vrácené parametry uvedeny v závorkách s uvedením jejich typů – v tomto případě pouze jednoho – Result.
Pokud by procedura neměla vracet parametry, pak chybí slovo RETURNS a seznam vrácených parametrů.
Po RETURNSQ je specifikováno klíčové slovo AS. Než odejde klíčové slovo AS titul, a po tom - techo postupy.
Tělo uložené procedury je seznam popisů jejích vnitřních (lokálních) proměnných (pokud existují, podíváme se na ně podrobněji níže), oddělených středníkem (;) a blokem příkazů uzavřeným v závorkách operátoru ZAČÁTEK KONEC. V tomto případě je tělo HP velmi jednoduché - požádáme o přidání dvou vstupních argumentů a jejich výsledek přiřadíme výstupnímu a poté zavoláme příkaz SUSPEND. O něco později si vysvětlíme podstatu akce tohoto příkazu, ale zatím jen poznamenáme, že je potřeba přenést návratové parametry tam, odkud byla uložená procedura volána.
Oddělovače v uložených procedurách
Všimněte si, že příkaz v proceduře končí středníkem (;). Jak víte, středník je standardní oddělovač příkazů v SQL - je to signál pro interpret SQL, že text příkazu byl zadán celý a měl by jej začít zpracovávat. Nedopadlo by to tak, že když SQL interpret najde uprostřed HP středník, bude předpokládat, že příkaz byl zadán celý a pokusí se provést část uložené procedury? Tento předpoklad není bezdůvodný. Pokud skutečně vytvoříte soubor, do kterého zapíšete výše uvedený příklad, přidáte příkaz pro připojení z databáze a pokusíte se spustit tento skript SQL pomocí interpretu isql, vrátí se chyba kvůli neočekávanému, podle názoru interpreta, ukončení příkazu pro vytvoření uložené procedury. Pokud vytváříte uložené procedury pomocí souborů skriptů SQL, bez použití specializovaných vývojářských nástrojů InterBase, pak před každým příkazem pro vytvoření HP (totéž platí pro spouštěče) musíte změnit oddělovač příkazů skriptu na jiný znak než středník a za textem HP jej obnovit zpět. Příkaz isql, který změní oddělovač klauzule SQL, vypadá takto:
SET TERM
Typický případ vytvoření uložené procedury vypadá takto:
SET TERM^;
CREATE PROCEDURE some_procedure
... . .
KONEC
^
SET TERM ;^
Volání uložené procedury
Ale vraťme se k naší uložené proceduře. Nyní, když byl vytvořen, musíte jej nějak zavolat, předat mu parametry a vrátit výsledky. To je velmi snadné - stačí napsat dotaz SQL takto:
VYBRAT *
FROM Sp_add(181,35; 23,09)
Tento dotaz nám vrátí jeden řádek obsahující právě jedno pole Výsledek, které bude obsahovat součet čísel 181,35 a 23,09, tedy 204,44.
Náš postup lze tedy použít v běžných SQL dotazech prováděných jak v klientských programech, tak v jiných HP nebo triggerech. Toto použití naší procedury je možné pomocí příkazu SUSPEND na konci uložené procedury.
Faktem je, že v InterBase (a ve všech jeho klonech) existují dva typy uložených procedur: volitelné procedury a spustitelné procedury. Rozdíl ve fungování těchto dvou typů HP spočívá v tom, že procedury vzorkování obvykle vracejí mnoho sad výstupních parametrů, seskupených řádek po řádku, které vypadají jako sada dat, zatímco spustitelné procedury buď nemohly vracet parametry vůbec, nebo vracet pouze jedna sada výstupních parametrů uvedená v Returns, kde jeden řádek parametrů. Procedury Select se volají v dotazech SELECT a spustitelné procedury se volají pomocí příkazu EXECUTE PROCEDURE.
Oba typy uložených procedur mají stejnou syntaxi vytváření a formálně se neliší, takže libovolnou spustitelnou proceduru lze volat v dotazu SELECT a libovolnou výběrovou proceduru lze volat pomocí EXECUTE PROCEDURE. Otázkou je, jak se bude HP chovat při různých typech hovorů. Jinými slovy, rozdíl spočívá v návrhu postupu pro konkrétní typ volání. To znamená, že procedura select je specificky vytvořena pro volání z dotazu SELECT a spustitelná procedura je specificky vytvořena pro volání pomocí EXECUTE PROCEDURE. Podívejme se, jaké jsou rozdíly v designu těchto dvou typů HP.
Abyste pochopili, jak postup vzorkování funguje, budete se muset ponořit trochu hlouběji do teorie. Představme si běžný SQL dotaz jako SELECT ID, NAME FROM Table_example. Jeho provedením získáme tabulku sestávající ze dvou sloupců (ID a NAME) a určitého počtu řádků (rovný počtu řádků v tabulce Table_example). Tabulka vrácená jako výsledek tohoto dotazu se také nazývá datová sada SQL Zamysleme se nad tím, jak se datová sada tvoří během provádění tohoto dotazu, server po obdržení dotazu určí, na které tabulky se odkazuje, a poté je najde zjistit, která podmnožina záznamů z těchto tabulek musí být zahrnuta do výsledku dotazu. Dále server přečte každý záznam, který vyhovuje výsledkům dotazu, vybere z něj požadovaná pole (v našem případě ID a NAME) a odešle je klientovi. Poté se proces znovu opakuje – a tak dále pro každý vybraný záznam.
Celá tato odbočka je nezbytná, aby milý čtenář pochopil, že všechny datové sady SQL jsou generovány řádek po řádku, včetně uložených procedur! A hlavní rozdíl mezi procedurami načítání a spustitelnými procedurami je v tom, že první jsou navrženy tak, aby vrátily mnoho řádků, zatímco druhé jsou navrženy tak, aby vrátily pouze jeden. Proto se používají jinak: procedura select je volána pomocí příkazu SELECT, který „vyžaduje“, aby se procedura vzdala všech záznamů, které může vrátit. Spustitelná procedura je volána pomocí EXECUTE PROCEDURE, která „vyjme“ pouze jeden řádek z HP a zbytek ignoruje (i když existují!).
Podívejme se na příklad postupu vzorkování, aby to bylo jasnější. Pro > odpuštění, vytvořme uloženou proceduru, která funguje přesně jako dotaz SELECT ID, NAME FROM Table_Example, to znamená, že jednoduše vybere pole ID a NAME z celé tabulky. Zde je tento příklad:
POSTUP VYTVOŘENÍ Simple_Select_SP
VRACÍ (
procID INTEGER,
procNAME VARCHAR(80))
TAK JAKO
ZAČÍT
PRO
SELECT ID, NAME FROM table_example
INTO:procID, :procNAME
DĚLAT
ZAČÍT
POZASTAVIT;
KONEC
KONEC
Podívejme se na kroky této procedury nazvané Simple_Select_SP. Jak vidíte, nemá žádné vstupní parametry a má dva výstupní parametry – ID a NAME. To nejzajímavější se samozřejmě skrývá v těle procedury. Zde se používá konstrukce FOR SELECT:
PRO
SELECT ID, NAME FROM table_example
INTO:procID, :procNAME
DĚLAT
ZAČÍT
/*udělejte něco s proměnnými procID a procName*/
KONEC
Tento kus kódu znamená následující: pro každý řádek vybraný z tabulky Table_example vložte vybrané hodnoty do proměnných procID a procName a poté s těmito proměnnými něco udělejte.
Možná uděláte překvapený obličej a zeptáte se: "Proměnné? Jaké další proměnné? 9" Je to jakési překvapení této kapitoly, že můžeme používat proměnné v uložených procedurách. V jazyce HP můžete v rámci procedury deklarovat jak své vlastní lokální proměnné, tak používat vstupní a výstupní parametry jako proměnné.
Chcete-li deklarovat lokální proměnnou v uložené proceduře, musíte její popis umístit za klíčové slovo AS a před první slovo BEGIN Popis lokální proměnné vypadá takto:
DEKLAROVAT PROMĚNNÉ
Chcete-li například deklarovat celočíselnou lokální proměnnou Mylnt, vložili byste následující deklaraci mezi AS a BEGIN
DECLARE VARIABLE Mylnt INTEGER;
Proměnné v našem příkladu začínají dvojtečkou. To je způsobeno tím, že jsou přístupné v rámci příkazu FOR SELECT SQL, takže pro rozlišení polí v tabulkách používaných v SELECTu a proměnných musí před nimi být dvojtečka. Proměnné se totiž mohou jmenovat úplně stejně jako pole v tabulkách!
Dvojtečka před názvem proměnné by se však měla používat pouze v dotazech SQL. Mimo texty se na proměnnou odkazuje bez dvojtečky, například:
procName="Nějaké jméno";
Ale vraťme se k tělu našeho postupu. Klauzule FOR SELECT vrací data nikoli ve formě tabulky – množiny dat, ale jeden řádek po druhém. Každé vrácené pole musí být umístěno ve své vlastní proměnné: ID => procID, NAME => procName. V části DO jsou tyto proměnné odeslány klientovi, který volal proceduru pomocí příkazu SUSPEND
Příkaz FOR SELECT...DO tedy prochází záznamy vybrané v části SELECT příkazu. V těle smyčky tvořené částí DO se další vygenerovaný záznam přenese klientovi pomocí příkazu SUSPEND.
Procedura výběru je tedy navržena tak, aby vrátila jeden nebo více řádků, pro které je uvnitř těla HP uspořádána smyčka, která vyplňuje výsledné proměnné parametry. A na konci těla této smyčky je vždy příkaz SUSPEND, který klientovi vrátí další řádek dat.
Smyčky a větvené příkazy
Kromě příkazu FOR SELECT...DO, který organizuje smyčku prostřednictvím záznamů výběru, existuje další typ smyčky - WHILE...DO, který umožňuje uspořádat smyčku na základě kontroly libovolných podmínek. Zde je příklad HP pomocí smyčky WHILE..DO. Tento postup vrátí druhé mocniny celých čísel od 0 do 99:
VYTVOŘTE PROCEDJRE QUAD
VRÁTKY (QUADRAT INTEGER)
TAK JAKO
DECLARE PROMĚNNÁ I CELÉ ČÍSLO;
ZAČÍT
I = 1;
Zatímco já<100) DO
ZAČÍT
QUADRAT= I*I;
I = 1+1;
POZASTAVIT;
KONEC
KONEC
V důsledku provedení dotazu SELECT FROM QUAD obdržíme tabulku obsahující jeden sloupec QUADRAT, který bude obsahovat druhé mocniny celých čísel od 1 do 99
Jazyk uložených procedur kromě iterace nad výsledky vzorku SQL a klasické smyčky používá operátor IF...THEN..ELSE, který umožňuje organizovat větvení v závislosti na provedení jakýchkoli podmínek. Jeho syntaxe je podobná většině větvících operátorů v programovacích jazycích na vysoké úrovni, jako je Pascal a C.
Podívejme se na složitější příklad uložené procedury, která provádí následující.
- Vypočítá průměrnou cenu v tabulce Table_example (viz kapitola "Tabulky Primární klíče a generátory")
- Dále pro každý záznam v tabulce provede následující kontrolu: pokud je stávající cena (PRICE) vyšší než průměrná cena, nastaví cenu rovnající se průměrné ceně plus stanovené pevné procento
- Pokud je stávající cena nižší nebo rovna průměrné ceně, pak se nastaví cena rovnající se předchozí ceně plus polovina rozdílu mezi předchozí a průměrnou cenou.
- Vrátí všechny upravené řádky v tabulce.
Nejprve si nadefinujme název HP a také vstupní a výstupní parametry To vše je zapsáno v hlavičce uložené procedury.
VYTVOŘIT POSTUP Zvýšit ceny (
Procent2lnzvýšení DVOJNÁSOBNÁ PŘESNOST)
VRÁCENÍ (ID INTEGER, NAME VARCHAR(SO), nová_cena DOUBLE
PRECISION AS
Procedura se bude jmenovat ZvýšitCeny, má jeden vstupní parametr Peiceni21nciease typu DOUBLE PRECISION a 3 výstupní parametry - ID, NAME a new_pnce. Všimněte si, že první dva výstupní parametry mají stejné názvy jako pole v tabulce Table_example, se kterou budeme pracovat. To umožňují pravidla jazyka uložené procedury.
Nyní musíme deklarovat lokální proměnnou, která bude použita k uložení průměrné hodnoty. Deklarace bude vypadat takto:
DECLARE VARIABLE avg_price DVOJNÁSOBNÁ PŘESNOST;
Nyní přejdeme k tělu uložené procedury Otevřete tělo HP
s klíčovým slovem BEGIN.
Nejprve musíme provést první krok našeho algoritmu – vypočítat průměrnou cenu. K tomu použijeme následující typ dotazu:
SELECT AVG(Cena_l)
FROM Table_Example
INTO:prům.cena,-
Tento dotaz používá agregační funkci AVG, která vrací průměr z pole PRICE_1 mezi vybranými řádky dotazu – v našem případě průměr z PRICE_1 v celé tabulce Table_example. Hodnota vrácená požadavkem je umístěna do proměnné avg_price. Všimněte si, že před proměnnou avg_pnce je dvojtečka, aby se odlišila od polí použitých v požadavku.
Zvláštností tohoto dotazu je, že vždy vrací právě jeden jediný záznam. Takové dotazy se nazývají jednoduché dotazy a pouze takové výběry lze použít v uložených procedurách. Pokud dotaz vrátí více než jeden řádek, musí být naformátován jako konstrukce FOR SELECT...DO, která organizuje smyčku pro zpracování každého vráceného řádku.
Takže jsme dostali průměrnou cenu. Nyní je třeba projít celou tabulku, porovnat hodnotu ceny v každém záznamu s průměrnou cenou a podniknout příslušné kroky
Od začátku organizujeme vyhledávání každého záznamu z tabulky Table_example
PRO
SELECT ID, NAME, PRICE_1
FROM Table_Example
INTO:ID, :NAME, :new_price
DĚLAT
ZAČÍT
/*_zde popisujeme každý záznam*/
KONEC
Když je tato konstrukce provedena, data budou extrahována z tabulky Table_example řádek po řádku a hodnoty polí v každém řádku budou přiřazeny proměnným ID, NAME a new_pnce. Samozřejmě si pamatujte, že tyto proměnné jsou deklarovány jako výstupní parametry, ale není třeba se obávat, že se vybraná data vrátí jako výsledky: skutečnost, že výstupním parametrům je něco přiřazeno, neznamená, že klient volající HP okamžitě obdrží tyto hodnoty! Parametry jsou předány pouze při provedení příkazu SUSPEND a předtím můžeme výstupní parametry použít jako běžné proměnné - v našem příkladu to uděláme právě s parametrem new_price.
Takže uvnitř těla smyčky BEGIN... END můžeme zpracovat hodnoty každého řádku. Jak si pamatujete, musíme zjistit, jaká je stávající cena ve srovnání s průměrem, a přijmout příslušná opatření. Tento postup porovnání implementujeme pomocí příkazu IF:
IF (new_price > avg_price) THEN /*pokud je stávající cena vyšší než průměrná cena*/
ZAČÍT
/*pak nastavíme novou cenu rovnající se průměrné ceně plus pevné procento */
nová_cena = (průměrná_cena + prům.cena*(procento2zvýšení/100));
UPDATE Table_example
SET PRICE_1 = :nová_cena
WHERE ID = :ID;
KONEC
JINÝ
ZAČÍT
/* Pokud je stávající cena nižší nebo rovna průměrné ceně, nastavte cenu rovnou předchozí ceně plus polovinu rozdílu mezi předchozí a průměrnou cenou */
nová_cena = (nová_cena + ((prům. nová_cena_pnce)/2)) ;
UPDATE Table_example
SET PRICE_1 = :nová_cena
WHERE ID = .ID;
KONEC
Jak vidíte, výsledkem je poměrně velký konstrukt IF, kterému by bylo těžké porozumět, nebýt komentářů uzavřených v symbolech /**/.
Pro změnu ceny v souladu s vypočteným rozdílem použijeme výpis UPDATE, který nám umožňuje upravit stávající záznamy - jeden nebo více. Abychom jednoznačně označili, ve kterém záznamu je potřeba cenu změnit, použijeme pole primárního klíče v podmínce WHERE, které porovnáme s hodnotou proměnné, která uchovává hodnotu ID pro aktuální záznam: ID=:ID. Všimněte si, že před proměnnou ID je dvojtečka.
Po provedení konstrukce IF...THEN...ELSE obsahují proměnné ID, NAME a new_price data, která musíme vrátit klientovi, který proceduru volal. K tomu je potřeba za IF vložit příkaz SUSPEND, který odešle data tam, odkud byl HP volán Při přenosu bude procedura pozastavena a při požadavku na nový záznam z HP, ano bude znovu pokračovat - a to bude pokračovat, dokud FOR SELECT...DO neprojde všechny záznamy ve svém dotazu.
Je třeba poznamenat, že kromě příkazu SUSPEND, který pouze pozastaví uloženou proceduru, existuje příkaz EXIT, který po předání řetězce uloženou proceduru ukončí. Příkaz EXIT se však používá poměrně zřídka, protože je potřeba hlavně k přerušení smyčky při dosažení podmínky
Avšak v případě, kdy byla procedura volána pomocí příkazu SELECT a dokončena pomocí EXIT, nebude vrácen poslední načtený řádek. To znamená, že pokud potřebujete přerušit proceduru a přesto >získat tento řetězec, musíte použít sekvenci
POZASTAVIT;
VÝSTUP;
Hlavním účelem EXITu je přijímat jednotlivé datové sady, vrácené parametry voláním EXECUTE PROCEDURE. V tomto případě jsou nastaveny hodnoty výstupních parametrů, ale datová sada SQL se z nich negeneruje a provádění procedury končí.
Pojďme si celý text naší uložené procedury zapsat, abychom na první pohled mohli zachytit její logiku:
VYTVOŘIT POSTUP Zvýšit ceny (
Percent2Zvýšení DVOJNÁSOBNÉ PŘESNOSTI)
VRÁCENÍ (INTEGER INTEGER, NAME VARCHAR(80),
nová_cena DVOJNÁSOBNÁ PŘESNOST) AS
DECLARE VARIABLE avg_price DVOJNÁSOBNÁ PŘESNOST;
ZAČÍT
SELECT AVG(Cena_l)
FROM Table_Example
INTO:prům.cena;
PRO
SELECT ID, NAME, PRICE_1
FROM Table_Example
INTO:ID, :NAME, :new_price
DĚLAT
ZAČÍT
/*zde zpracuj každý záznam*/
IF (new_pnce > avg_price) THEN /*pokud je stávající cena vyšší než průměrná cena*/
ZAČÍT
/*nastavit novou cenu rovnající se průměrné ceně plus pevné procento */
nová_cena = (průměrná_cena + prům.cena*(procento 2lnzvýšení/100));
UPDATE Table_example
SET PRICE_1 = :nová_cena
WHERE ID = :ID;
KONEC
JINÝ
ZAČÍT
/* Pokud je stávající cena nižší nebo rovna průměrné ceně, nastaví cenu rovnou předchozí ceně plus polovinu rozdílu mezi předchozí a průměrnou cenou */
nová_cena = (nová_cena + ((prům.cena - nová_cena)/2));
UPDATE Table_example
SET PRICE_1 = :nová_cena
WHERE ID = :ID;
KONEC
POZASTAVIT;
KONEC
KONEC
Tento příklad uložené procedury ilustruje použití základních konstrukcí a spouštěčů jazyka uložených procedur. Dále se podíváme na způsoby použití uložených procedur k řešení některých běžných problémů.
Rekurzivní uložené procedury
Uložené procedury InterBase mohou být rekurzivní. To znamená, že uložená procedura může volat sama sebe. Je povoleno až 1000 úrovní vnoření uložených procedur, ale musíme mít na paměti, že volné prostředky na serveru mohou dojít dříve, než bude dosaženo maximálního vnoření HP.
Jedním z běžných použití uložených procedur je zpracování stromových struktur uložených v databázi. Stromy se často používají ve složení produktů, skladech, personálu a dalších běžných aplikacích.
Podívejme se na příklad uložené procedury, která vybírá všechny produkty určitého typu počínaje určitou úrovní vnoření.
Mějme následující formulaci problému: máme adresář zboží s hierarchickou strukturou následujícího typu:
Zboží
- Spotřebiče
- Ledničky
- Tříkomorový
- Dvoukomorový
- Jednokomorový
- Pračky
- Vertikální
- Přední
- Klasika
- Úzký
- Počítačová technologie
....
Tato struktura adresáře kategorií produktů může mít větve s různou hloubkou. a také se časem zvyšují. Naším úkolem je zajistit výběr všech konečných prvků z adresáře s "rozšířením celého jména", počínaje libovolným uzlem. Pokud například vybereme uzel „Pračky“, musíme získat následující kategorie:
Pračky - Vertikální
Pračky - Přední Classic
Pračky - Přední Úzká
Pojďme definovat strukturu tabulky pro ukládání informací o produktovém adresáři. K uspořádání stromu do jedné tabulky používáme zjednodušené schéma:
VYTVOŘIT TABULKU Strom zboží
(ID_GOOD INTEGER NENÍ NULL,
ID_PARENT_GOOD INTEGER,
GOOD_NAME VARCHAR(80),
omezení primární klíč pkGooci (ID_GOOD));
Vytvoříme jednu tabulku GoodsTree, ve které jsou pouze 3 pole: ID_GOOD - chytrý identifikátor kategorie, ID_PARENT_GOOD - identifikátor mateřské společnosti pro tuto kategorii a GOOD_NAME - název kategorie. Abychom zajistili integritu dat v této tabulce, uvalíme na tuto tabulku omezení cizího klíče:
ALTER TABLE ZbožíStrom
PŘIDAT OMEZENÍ FK_goodstree
CIZÍ KLÍČ (ID_PARENT_GOOD)
REFERENCE GOODSTPEE (ID__GOOD)
Tabulka odkazuje sama na sebe a tento cizí klíč to sleduje. aby tabulka neobsahovala odkazy na neexistující rodiče a také zabránila pokusům o odstranění kategorií produktů, které mají potomky.
Zadejme do naší tabulky následující údaje:
| ID_GOOD 1
|
ID_PARENT_GOOD 0
|
DOBRÉ JMÉNO ZBOŽÍ |
Nyní, když máme místo pro uložení dat, můžeme začít vytvářet uloženou proceduru, která vypíše všechny „finální“ kategorie produktů v „rozbalené“ podobě – například pro kategorii „Tříkomorová“ celá kategorie název by byl "Chladničky pro domácnost" Tříkomorové".
Uložené procedury, které zpracovávají stromové struktury, mají svou vlastní terminologii. Každý prvek stromu se nazývá uzel; a vztah mezi uzly, které na sebe odkazují, se nazývá vztah rodič-dítě. Uzly, které jsou na samém konci stromu a nemají žádné potomky, se nazývají „listy“.
Pro tuto uloženou proceduru bude vstupním parametrem identifikátor kategorie, od kterého budeme muset spustit rozbor. Uložená procedura bude vypadat takto:
CREATE PROCEDURE GETFULLNAME (ID_GOOD2SHOW INTEGER)
VRÁCENÍ (FULL_GOODS_NAME VARCHAR(1000),
ID_CHILD_GOOD INTEGER)
TAK JAKO
DECLARE VARIABLE CURR_CHILD_NAME VARCHAR(80);
ZAČÍT
/*0organizujte vnější smyčku FOR SELECT podle přímých potomků produktu s ID_GOOD=ID_GOOD2SHOW */
FOR SELECT gtl.id_good, gtl.good_name
FROM GoodsTree gtl
WHERE gtl.id_parent_good=:ID_good2show
INTO:ID_CHILD_GOOD, :full_goods_name
DĚLAT
ZAČÍT
/"Zkontrolujte pomocí funkce EXISTS, která vrátí hodnotu TRUE, pokud dotaz v závorkách vrátí alespoň jeden řádek. Pokud nalezený uzel s ID_PARENT_GOOD = ID_CHILD_GOOD nemá žádné potomky, pak je to „list“ stromu a je zahrnut ve výsledcích */
POKUD (NEEXISTUJE(
VYBERTE * ZE Stromu zboží
WHERE GoodsTree.id_parent_good=:id_child_good))
PAK
ZAČÍT
/* Předejte „list“ stromu výsledkům */
POZASTAVIT;
KONEC
JINÝ
/* Pro uzly, které mají potomky*/
ZAČÍT
/*uložte název nadřazeného uzlu do dočasné proměnné */
CURR_CHILD_NAME=úplný_název_zboží;
/* spusťte tuto proceduru rekurzivně */
PRO
SELECT ID_CHILD_GOOD, full_goods_name
FROM GETFULLNAME (:ID_CHILD_GOOD)
INTO:ID_CHILD_GOOD, :full_goods_name
ZAČNĚTE
/*přidání názvu nadřazeného uzlu k nalezenému podřízenému jménu pomocí operace zřetězení řetězců || */
full_goods_name=CURR_CHILD_NAME| " " | celé jméno_zboží,-
POZASTAVIT; /* vrátit celý název produktu*/
KONEC
KONEC
KONEC
KONEC
Pokud tento postup provedeme se vstupním parametrem ID_GOOD2SHOW= 1, dostaneme následující:
Jak vidíte, pomocí rekurzivní uložené procedury jsme prošli celý strom kategorií a zobrazili celé názvy kategorií „listů“, které se nacházejí na úplných špičkách větví.
Závěr
Tím končí naše úvaha o hlavních rysech jazyka uložených procedur. Je zřejmé, že není možné plně zvládnout vývoj uložených procedur v jedné kapitole, ale zde jsme se pokusili představit a vysvětlit základní pojmy spojené s uloženými procedurami. Popsané návrhy a techniky pro návrh HP lze použít ve většině databázových aplikací
Některým důležitým otázkám souvisejícím s vývojem uložených procedur se budeme věnovat v další kapitole – „Pokročilé možnosti jazyka uložených procedur InterBase“, která je věnována zpracování výjimek, řešení chybových situací v uložených procedurách a práci s poli.
SQL - Lekce 15. Uložené procedury. Část 1.
Zpravidla při práci s databází používáme stejné dotazy, případně sadu sekvenčních dotazů. Uložené procedury umožňují kombinovat posloupnost dotazů a ukládat je na server. Toto je velmi pohodlný nástroj a nyní to uvidíte. Začněme syntaxí:CREATE PROCEDURE název_procedury (parametry) begin příkazy konec
Parametry jsou data, která předáme proceduře při jejím volání, a operátory jsou samotné požadavky. Pojďme si napsat náš první postup a přesvědčte se, že je to pohodlné. V lekci 10, když jsme přidali nové záznamy do databáze obchodu, jsme použili standardní dotaz k přidání formuláře:
INSERT INTO customers (jméno, email) VALUE ("Ivanov Sergey", " [e-mail chráněný]");
Protože Podobný požadavek použijeme pokaždé, když potřebujeme přidat nového zákazníka, je tedy docela vhodné jej formalizovat ve formě postupu:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50)) začít vkládat do zákazníků (jméno, email) hodnotu (n, e); konec
Věnujte pozornost tomu, jak jsou parametry zadány: musíte parametru pojmenovat a uvést jeho typ a v těle procedury již používáme názvy parametrů. Jedno upozornění. Jak si pamatujete, středník znamená konec požadavku a odešle jej k provedení, což je v tomto případě nepřijatelné. Proto před napsáním procedury musíte předefinovat oddělovač c; na "//", aby požadavek nebyl odeslán předem. To se provádí pomocí operátoru DELIMITER //: 
Proto jsme DBMS naznačili, že příkazy by se nyní měly provádět po //. Je třeba si uvědomit, že předefinování oddělovače se provádí pouze pro jednu relaci, tzn. při další práci s MySql se z oddělovače opět stane středník a v případě potřeby se bude muset znovu definovat. Nyní můžete umístit postup:
CREATE PROCEDURE ins_cust(n CHAR(50), e CHAR(50)) začít vkládat do zákazníků (jméno, email) hodnotu (n, e); konec //

Postup byl tedy vytvořen. Nyní, když potřebujeme zadat nového zákazníka, stačí mu zavolat a zadat potřebné parametry. K volání uložené procedury použijte příkaz CALL následovaný názvem procedury a jejími parametry. Pojďme přidat nového zákazníka do naší tabulky Zákazníci:
call ins_cust("Sychov Valery", " [e-mail chráněný]")//

Souhlaste s tím, že je to mnohem jednodušší, než pokaždé napsat celou žádost. Zkontrolujeme, zda postup funguje, a podívejme se, zda se v tabulce Zákazníci objevil nový zákazník:

Objevil se, postup funguje a bude fungovat vždy, dokud jej neodstraníme pomocí operátoru DROP PROCEDURE název_procedury.
Jak bylo zmíněno na začátku lekce, procedury umožňují kombinovat posloupnost dotazů. Pojďme se podívat, jak se to dělá. Pamatujete si, že v lekci 11 jsme chtěli vědět, za kolik nám dodavatel „House of Printing“ přinesl zboží? K tomu jsme museli použít poddotazy, spojení, počítané sloupce a pohledy. Co když chceme vědět, za kolik nám zboží dovezl druhý dodavatel? Budete muset vytvořit nové dotazy, spojení atd. Jednodušší je napsat uloženou proceduru pro tuto akci.
Zdálo by se, že nejjednodušším způsobem je vzít pohled a dotaz na něj již napsaný v lekci 11, zkombinovat je do uložené procedury a učinit z identifikátoru dodavatele (id_vendor) vstupní parametr, jako je tento:
VYTVOŘIT POSTUP sum_vendor(i INT) begin VYTVOŘIT ZOBRAZIT report_vendor JAKO VYBERTE časopis_příchozí.id_produkt, příchozí_množství v časopise, ceny.cena, příchozí_množství*ceny.cena JAKO součet Z příchozího_časopisu, ceny KDE časopis_příchozí.id_produkt= id_příchozí_produkt=produkt_id_cz SELECT id_incoming FROM incoming WHERE id_vendor=i); SELECT SUM(součet) FROM report_vendor; konec //
Takto ale postup fungovat nebude. Celá podstata je v tom pohledy nemohou používat parametry. Proto budeme muset mírně změnit pořadí požadavků. Nejprve vytvoříme pohled, který bude zobrazovat ID dodavatele (id_vendor), ID produktu (id_product), množství (množství), cenu (cena) a součet (součet) ze tří tabulek Zásoby (příchozí), Zásobník (příchozí_časopis) , Ceny ( ceny):
VYTVOŘIT ZOBRAZENÍ report_vendor JAKO VÝBĚR příchozí.id_vendor, časopis_příchozí.id_produkt, časopis_příchozí.množství, ceny.cena, časopis_příchozí.množství*ceny.cena JAKO součet Z příchozích, příchozí_časopisy, ceny KDE časopis_příchozí.id_produkt=příchody.id_příchozí_produkt A_příchozí_číslo_časopisu .id_incoming;
A pak vytvoříme dotaz, který bude sumarizovat množství dodávek dodavatele, o kterého máme zájem, například s id_vendor=2:
Nyní můžeme tyto dva dotazy zkombinovat do uložené procedury, kde vstupním parametrem bude identifikátor dodavatele (id_vendor), který bude nahrazen do druhého dotazu, ale ne do pohledu:
VYTVOŘIT POSTUP sum_vendor(i INT) begin VYTVOŘIT ZOBRAZIT report_vendor JAKO VYBERTE příchozí.id_vendor, časopis_příchozí.id_produkt, časopis_příchozí.množství, ceny.cena, množství_příchozích_časopisů*ceny.cena JAKO součet FROM příchozí,_příchozí_časopis, ceny KDE_příchozí_produkt_ceny_časopisu=přicházející_produkt_časopisu .id_product AND magazine_incoming.id_incoming= příchozí.id_příchozí; SELECT SUM(součet) FROM report_vendor WHERE id_vendor=i; konec //

Pojďme zkontrolovat fungování procedury s různými vstupními parametry:

Jak vidíte, procedura se spustí jednou a pak vyvolá chybu, která nám říká, že pohled report_vendor již v databázi existuje. Je to proto, že při prvním volání procedury se vytvoří pohled. Při druhém přístupu se pokusí znovu vytvořit pohled, ale ten již existuje, a proto se zobrazí chyba. Aby se tomu zabránilo, existují dvě možnosti.
První je vyřadit zastoupení z řízení. To znamená, že pohled vytvoříme jednou a procedura k němu pouze přistoupí, ale nevytvoří jej. Nezapomeňte smazat již vytvořenou proceduru a nejprve si prohlédnout:
DROP PROCEDURE sum_vendor// DROP VIEW report_vendor// VYTVOŘIT ZOBRAZENÍ report_vendor JAKO VYBERTE příchozí.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming. = prices.id_product AND magazine_incoming.id_incoming= incoming.id_incoming // VYTVOŘENÍ POSTUPU sum_vendor(i INT) begin SELECT SUM(summa) FROM report_vendor WHERE id_vendor=i; konec //
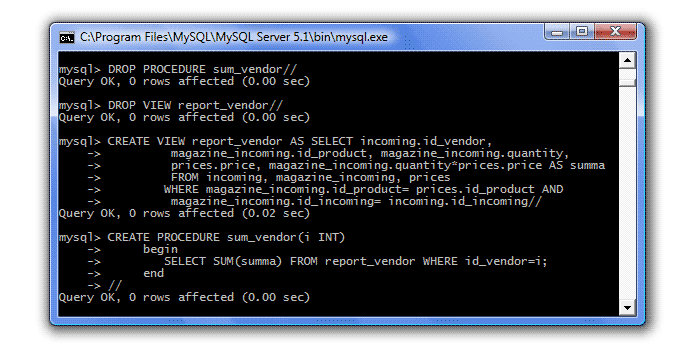
Kontrola práce:
call sum_vendor(1)// call sum_vendor(2)// call sum_vendor(3)//

Druhou možností je přidat příkaz přímo do procedury, která odstraní pohled, pokud existuje:
CREATE PROCEDURE sum_vendor(i INT) begin DROP VIEW IF EXISTS report_vendor; VYTVOŘIT ZOBRAZENÍ report_vendor JAKO VÝBĚR příchozí.id_vendor, časopis_příchozí.id_produkt, časopis_příchozí.množství, ceny.cena, časopis_příchozí.množství*ceny.cena JAKO součet Z příchozích, příchozí_časopisy, ceny KDE časopis_příchozí.id_produkt=příchody.id_příchozí_produkt A_příchozí_číslo_časopisu .id_incoming; SELECT SUM(součet) FROM report_vendor WHERE id_vendor=i; konec //
Před použitím této možnosti se ujistěte, že jste odstranili proceduru sum_vendor a poté otestujte práci: 
Jak vidíte, je opravdu snazší jednou formalizovat složité dotazy nebo jejich sekvenci do uložené procedury a pak k ní jednoduše přistupovat a zadat potřebné parametry. To výrazně redukuje kód a dělá práci s dotazy logičtější.
Cíl práce– naučit se vytvářet a používat uložené procedury na databázovém serveru.
1. Projděte všechny příklady a analyzujte výsledky jejich provedení v nástroji SQL Server Management Studio. Kontrola přítomnosti vytvořených procedur v aktuální databázi.
2. Dokončení všech příkladů a úkolů při laboratorní práci.
3. Plnění jednotlivých úkolů dle možností.
Vysvětlivky k provedení práce
Pro zvládnutí programování uložených procedur používáme ukázkovou databázi tzv DB_Books, která vznikla v laboratorní práci č.1. Při vyplňování příkladů a úkolů dbejte na shodu názvů databáze, tabulek a dalších objektů projektu.
Uložené procedury jsou souborem příkazů skládajících se z jednoho nebo více SQL příkazů nebo funkcí a uložených v databázi v kompilované podobě.
Typy uložených procedur
Systémové uložené procedury jsou navrženy k provádění různých administrativních akcí. Téměř všechny činnosti správy serveru jsou prováděny s jejich pomocí. Dá se říci, že systémové uložené procedury jsou rozhraním, které zajišťuje práci se systémovými tabulkami. Systémové uložené procedury mají předponu sp_, jsou uloženy v systémové databázi a lze je volat v kontextu jakékoli jiné databáze.
Vlastní uložené procedury implementují určité akce. Uložené procedury jsou plnohodnotným databázovým objektem. V důsledku toho je každá uložená procedura umístěna v určité databázi, kde se provádí.
Dočasně uložené procedury existují pouze krátkou dobu, po které jsou serverem automaticky zničeny. Dělí se na lokální a globální. Místní dočasně uložené procedury lze volat pouze z připojení, ve kterém jsou vytvořeny. Při vytváření takové procedury jí musíte dát název, který začíná jedním znakem #. Stejně jako všechny dočasné objekty jsou uložené procedury tohoto typu automaticky odstraněny, když se uživatel odpojí nebo restartuje nebo zastaví server. Globální dočasné uložené procedury jsou dostupné pro všechna připojení ze serveru, který má stejný postup. Chcete-li jej definovat, stačí jej pojmenovat začínající znaky ##. Tyto procedury jsou odstraněny při restartování nebo zastavení serveru nebo po uzavření připojení v kontextu, ve kterém byly vytvořeny.
Vytváření, úpravy uložených procedur
Vytvoření uložené procedury zahrnuje řešení následujících problémů: plánování přístupových práv. Když vytvoříte uloženou proceduru, uvědomte si, že bude mít stejná přístupová práva k databázovým objektům jako uživatel, který ji vytvořil; definování parametrů uložené procedury mohou mít vstupní a výstupní parametry; vývoj kódu uložené procedury. Kód procedury může obsahovat sekvenci libovolných příkazů SQL, včetně volání jiných uložených procedur.
Syntaxe operátoru pro vytvoření nové nebo změny existující uložené procedury v notaci MS SQL Server:
( CREATE | ALTER ) PROC[ EDURE] název_procedury [ ;číslo] [ ( @název_parametru typ_dat ) [ VARYING ] [ = VÝCHOZÍ ] [ VÝSTUP ] ] [ ,... n] [ WITH ( PŘEKOMPILOVAT | ŠIFROVÁNÍ | PŘEKOMPILOVAT, ŠIFROVAT )] [ FOR REPLICATION] JAKO příkaz sql [ ... n]Podívejme se na parametry tohoto příkazu.
Pomocí prefixů sp_, #, ## lze vytvořenou proceduru definovat jako systémovou nebo dočasnou. Jak je patrné ze syntaxe příkazu, není dovoleno uvádět jméno vlastníka, který bude vlastnit vytvořenou proceduru, a také název databáze, kde se má nacházet. Chcete-li tedy uloženou proceduru, kterou vytváříte, umístit do určité databáze, musíte zadat příkaz CREATE PROCEDURE v kontextu této databáze. Při přístupu k objektům stejné databáze z těla uložené procedury můžete použít zkrácené názvy, tj. bez zadání názvu databáze. Pokud potřebujete přistupovat k objektům umístěným v jiných databázích, je zadání názvu databáze povinné.
Chcete-li předat vstupní a výstupní data, musí názvy parametrů v uložené proceduře, kterou vytvoříte, začínat znakem @. V jedné uložené proceduře můžete zadat více parametrů oddělených čárkami. Tělo procedury by nemělo používat lokální proměnné, jejichž názvy se shodují s názvy parametrů této procedury. Pro určení datového typu parametrů uložené procedury je vhodný jakýkoli datový typ SQL, včetně uživatelsky definovaných. Datový typ CURSOR lze ale použít pouze jako výstupní parametr uložené procedury, tzn. zadáním klíčového slova OUTPUT.
Přítomnost klíčového slova OUTPUT znamená, že odpovídající parametr má vrátit data z uložené procedury. To však neznamená, že parametr není vhodný pro předávání hodnot do uložené procedury. Zadání klíčového slova OUTPUT dává serveru pokyn, aby při ukončení uložené procedury přiřadil aktuální hodnotu parametru lokální proměnné, která byla zadána jako hodnota parametru při volání procedury. Všimněte si, že při zadávání klíčového slova OUTPUT lze hodnotu odpovídajícího parametru při volání procedury nastavit pouze pomocí lokální proměnné. Jakékoli výrazy nebo konstanty, které jsou povoleny pro normální parametry, nejsou povoleny. Klíčové slovo VARYING se používá ve spojení s parametrem OUTPUT, který je typu CURSOR. Určuje, že výstupem bude sada výsledků.
Klíčové slovo DEFAULT představuje hodnotu, kterou bude mít odpovídající parametr ve výchozím nastavení. Při volání procedury tedy nemusíte explicitně specifikovat hodnotu odpovídajícího parametru.
Vzhledem k tomu, že server ukládá do mezipaměti plán provádění dotazu a zkompilovaný kód, při příštím volání procedury se použijí hotové hodnoty. V některých případech je však stále nutné znovu zkompilovat kód procedury. Zadáním klíčového slova PŘEKOMPILOVAT dává systému pokyn k vytvoření plánu provádění pro uloženou proceduru při každém jejím volání.
Parametr FOR REPLICATION je vyžadován při replikaci dat a zahrnutí vytvořené uložené procedury jako článku v publikaci. Klíčové slovo ENCRYPTION dává serveru pokyn, aby zašifroval kód uložené procedury, což může poskytnout ochranu proti použití proprietárních algoritmů, které implementují uloženou proceduru. Klíčové slovo AS je umístěno na začátek samotného těla uložené procedury. Tělo procedury může používat téměř všechny příkazy SQL, deklarovat transakce, nastavovat zámky a volat další uložené procedury. Uloženou proceduru můžete ukončit pomocí příkazu RETURN.
Odebrání uložené procedury
DROP PROCEDURE (název_procedury) [,... n]
Provedení uložené procedury
Chcete-li spustit uloženou proceduru, použijte příkaz: [ [ EXEC [ UTE] název_procedury [ ;číslo] [ [ @název_parametru= ] ( hodnota | @název_proměnné) [ VÝSTUP ] | [ VÝCHOZÍ ] ] [ ,... n]
Pokud volání uložené procedury není jediným příkazem v dávce, je vyžadován příkaz EXECUTE. Tento příkaz je navíc vyžadován k volání procedury z těla jiné procedury nebo spouštěče.
Použití klíčového slova OUTPUT při volání procedury je povoleno pouze pro parametry, které byly deklarovány při vytvoření procedury pomocí klíčového slova OUTPUT.
Když je pro parametr při volání procedury zadáno klíčové slovo DEFAULT, použije se výchozí hodnota. Zadané slovo DEFAULT je přirozeně povoleno pouze pro ty parametry, pro které je definována výchozí hodnota.
Syntaxe příkazu EXECUTE ukazuje, že názvy parametrů lze při volání procedury vynechat. V tomto případě však musí uživatel zadat hodnoty parametrů ve stejném pořadí, v jakém byly uvedeny při vytváření procedury. Parametru nemůžete přiřadit výchozí hodnotu tak, že ji během výčtu jednoduše vynecháte. Pokud chcete vynechat parametry, které mají výchozí hodnotu, stačí při volání uložené procedury explicitně zadat názvy parametrů. Navíc tímto způsobem můžete vypsat parametry a jejich hodnoty v libovolném pořadí.
Všimněte si, že při volání procedury jsou zadány buď názvy parametrů s hodnotami, nebo pouze hodnoty bez názvu parametru. Jejich kombinování není povoleno.
Použití RETURN v uložené proceduře
Umožňuje ukončit postup v kterémkoli bodě podle zadané podmínky a také umožňuje sdělit výsledek postupu jako číslo, podle kterého můžete posoudit kvalitu a správnost postupu. Příklad vytvoření procedury bez parametrů:
VYTVOŘIT POSTUP Count_Books AS SELECT COUNT (číselník) Z Books GOCvičení 1.
EXEC Count_BooksZkontrolujte výsledek.
Příklad vytvoření procedury se vstupním parametrem:
POSTUP VYTVOŘENÍ Count_Books_Pages @Count_pages AS INT AS SELECT COUNT (Číselník) FROM Books WHERE Pages>= @Count_pages GOÚkol 2. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazu
EXEC Count_Books_Pages 100Zkontrolujte výsledek.
Příklad vytvoření procedury se vstupními parametry:
CREATE PROCEDURE Count_Books_Title @Count_pages AS INT , @Title AS CHAR (10 ) AS SELECT COUNT (Číselník) FROM Books WHERE Pages>= @Count_pages AND Title_book LIKE @Title GOÚkol 3. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazu
EXEC Count_Books_Title 100, "P%"Zkontrolujte výsledek.
Příklad vytvoření procedury se vstupními parametry a výstupním parametrem:
POSTUP VYTVOŘENÍ Count_Books_Itogo @Count_pages INT , @Title CHAR (10) , @Itogo INT OUTPUT AS SELECT @Itogo = COUNT (Číselník) FROM Books WHERE Pages>= @Count_pages AND Title_book LIKE @Title GOÚkol 4. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte pomocí sady příkazů:
Sql> Declare @q As int EXEC Count_Books_Itogo 100, "P%", @q output select @q
Zkontrolujte výsledek.
Příklad vytvoření procedury se vstupními parametry a RETURN:
CREATE PROCEDURE checkname @param INT AS IF (SELECT Name_author FROM autorů WHERE Code_author = @param) = "Pushkin A.S." VRÁTIT 1 JINÝ VRÁTIT 2Úkol 5. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazů:
DECLARE @return_status INT EXEC @return_status = kontrolní jméno 1 VYBERTE "Stav návratu" = @return_statusPříklad vytvoření procedury bez parametrů pro zvýšení hodnoty klíčového pole v tabulce Nákupy dvakrát:
CREATE PROC update_proc AS UPDATE Nákupy SET Code_purchase = Code_purchase* 2Úkol 6. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazu
EXEC update_procPříklad procedury se vstupním parametrem pro získání všech informací o konkrétním autorovi:
CREATE PROC select_author @k CHAR (30 ) AS SELECT * FROM Authors WHERE name_author= @kÚkol 7.
EXEC select_author "Pushkin A.S." nebo select_author @k= "Pushkin A.S." nebo EXEC select_author @k= "Pushkin A.S."Příklad vytvoření procedury se vstupním parametrem a výchozí hodnotou pro zvýšení hodnoty klíčového pole v tabulce Nákupy o zadaný počet opakování (ve výchozím nastavení 2krát):
CREATE PROC update_proc @p INT = 2 JAKO AKTUALIZACE Nákupy SET Code_purchase = Code_purchase * @pProcedura nevrací žádná data.
Úkol 8. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazů:
EXEC update_proc 4 nebo EXEC update_proc @p = 4 nebo EXEC update_proc --bude použita výchozí hodnota.Příklad vytvoření procedury se vstupními a výstupními parametry. Vytvořte postup pro určení počtu objednávek dokončených během zadaného období:
CREATE PROC count_purchases @d1 SMALLDATETIME, @d2 SMALLDATETIME, @c INT OUTPUT AS SELECT @c= COUNT (Code_purchase) FROM Nákupy WHERE Date_order BETWEEN @d1 AND @d2 SET @c = ISNULL(@c, 0 )Úkol 9. Vytvořte tuto proceduru v části Uložené procedury databáze DB_Books pomocí nástroje SQL Server Management Studio. Spusťte jej pomocí příkazů:
DECLARE @c2 INT EXEC count_purchases '01-jun-2006', '01-jul-2006', @c2 OUTPUT SELECT @c2Možnosti úloh pro laboratorní práci č. 4
Obecná ustanovení. V nástroji SQL Server Management Studio vytvořte novou stránku pro kód (tlačítko „Vytvořit dotaz“). Vytvořenou databázi DB_Books programově aktivujte pomocí příkazu Use. Vytvořte uložené procedury pomocí příkazů Create procedure a definujte názvy procedur sami. Každá procedura provede jeden SQL dotaz, který byl proveden ve druhém cvičení. Navíc je třeba změnit kód SQL dotazů, aby mohly přenášet hodnoty polí používaných k vyhledávání.
Například úvodní úkol a požadavek v laboratorní práci č. 2:
/*Vyberte z adresáře dodavatelů (tabulka dodávek) názvy společností, telefonní čísla a INN (pole Name_company, Phone a INN), jejichž název společnosti (pole Name_company) je „OJSC MIR“.
SELECT Name_company, Phone, INN FROM Delivery WHERE Name_company = "OJSC MIR"*/ –V této práci bude vytvořen následující postup:
CREATE PROC select_name_company @comp CHAR (30 ) AS SELECT Name_company, Phone, INN FROM Dodávky WHERE Name_company = @comp– Pro zahájení postupu použijte příkaz:
EXEC select_name_company "JSC MIR"Seznam úkolů
Vytvořte nový program v SQL Server Management Studio. Programově aktivujte individuální databázi vytvořenou v laboratorní práci č. 1 pomocí příkazu Use. Vytvořte uložené procedury pomocí příkazů Create procedure a definujte názvy procedur sami. Každá procedura provede jeden SQL dotaz, který je prezentován formou samostatných úloh podle možností.
Možnost 1
1. Zobrazte seznam zaměstnanců, kteří mají alespoň jedno dítě.
2. Zobrazte seznam dětí, které v určeném období dostaly dárky.
3. Zobrazte seznam rodičů, kteří mají nezletilé děti.
4. Zobrazte informace o dárcích s hodnotou větší než zadané číslo, seřazené podle data.
Možnost 2
1. Zobrazte seznam zařízení se zadaným typem.
2. Zobrazte počet opravených zařízení a celkové náklady na opravy od zadaného technika.
3. Zobrazte seznam vlastníků zařízení a počet jejich požadavků seřazený podle počtu požadavků v sestupném pořadí.
4. Zobrazte informace o řemeslnících s vyšší hodností než zadaný počet nebo s datem nástupu do zaměstnání nižším než zadané datum.
Možnost 3
2. Zobrazte seznam prodejních kódů, které prodávaly květiny za částku vyšší než zadané číslo.
3. Zobrazte datum prodeje, množství, prodejce a květinu dle zadaného prodejního kódu.
4. Zobrazte seznam květin a odrůdy pro květiny s výškou větší než zadaný počet nebo kvetoucí.
Možnost 4
1. Zobrazte seznam léků se zadanou indikací k použití.
2. Zobrazte seznam dodacích termínů, za které bylo prodáno více než zadané množství stejnojmenného léku.
3. Zobrazte datum dodání, množství, celé jméno vedoucího od dodavatele a název léku kódem účtenky větším než zadané číslo.
Možnost 5
2. Zobrazte seznam vyřazených zařízení ze zadaného důvodu.
3. U zařízení odepsaného během stanoveného období zobrazte datum přijetí, název zařízení, celé jméno odpovědné osoby a datum odpisu.
4. Zobrazte seznam zařízení se zadaným typem nebo s datem příjmu vyšším než určitá hodnota
Možnost 6
1. Zobrazte seznam pokrmů s hmotností větší než zadané číslo.
2. Zobrazte seznam produktů, jejichž názvy obsahují zadaný fragment slova.
3. Zobrazte objem produktu, název pokrmu, název produktu s kódem pokrmu od zadané počáteční hodnoty po určitou konečnou hodnotu.
4. Zobrazte pořadí přípravy pokrmu a název pokrmu s množstvím sacharidů vyšším než určitá hodnota nebo množstvím kalorií vyšším než zadaná hodnota.
Možnost 7
1. Zobrazte seznam zaměstnanců se zadanou pozicí.
3. U dokumentů registrovaných během zadaného období zobrazte datum registrace, typ dokumentu, celé jméno registrátora a název organizace.
4. Zobrazte seznam evidovaných dokumentů s určitým typem dokumentu nebo s datem registrace vyšším než zadaná hodnota.
Možnost 8
1. Zobrazte seznam zaměstnanců se zadaným důvodem propuštění.
3. U dokumentů evidovaných v uvedeném období zobrazte datum registrace, důvod propuštění, celé jméno zaměstnance.
Možnost 9
1. Zobrazte seznam zaměstnanců, kteří čerpali dovolenou zadaného typu.
2. Zobrazte seznam dokumentů s datem registrace v zadaném období.
3. U dokladů evidovaných v zadaném období zobrazte datum přihlášení, druh dovolené, celé jméno zaměstnance.
4. Zobrazte seznam registrovaných dokumentů s kódem dokumentu v zadaném rozsahu.
Možnost 10
1. Zobrazte seznam zaměstnanců se zadanou pozicí.
2. Zobrazte seznam dokumentů, jejichž obsah obsahuje zadaný fragment slova.
3. U dokumentů registrovaných během zadaného období zobrazte datum registrace, typ dokumentu, celé jméno odesílatele a název organizace.
4. Zobrazte seznam registrovaných dokumentů se zadaným typem dokumentu nebo s kódem dokumentu menším než určitá hodnota.
Možnost 11
1. Zobrazte seznam zaměstnanců zařazených na zadanou pozici.
2. Zobrazte seznam dokumentů s datem registrace v zadaném období.
3. U dokumentů evidovaných v zadaném období zobrazte datum registrace, pozici, celé jméno zaměstnance.
4. Zobrazte seznam registrovaných dokumentů s kódem dokumentu v zadaném rozsahu.
Možnost 12
3. Zobrazte seznam lidí, kteří si pronajali vybavení, a počet jejich požadavků seřazený podle počtu požadavků v sestupném pořadí.
Možnost 13
1. Zobrazte seznam zařízení se zadaným typem. 2. Zobrazte seznam zařízení, které bylo odepsáno konkrétním zaměstnancem.
3. Zobrazte množství vyřazeného zařízení seskupené podle typu zařízení.
4. Zobrazte informace o zaměstnancích s datem přijetí vyšším než určité datum.
Možnost 14
1. Vytiskněte seznam květin se zadaným typem listu.
2. Zobrazte seznam kódů účtenek, za které byly květiny prodány za částky vyšší než určitá hodnota.
3. Zobrazte datum příjmu, množství, název dodavatele a barvy podle specifického kódu dodavatele.
4. Zobrazte seznam květin a odrůdy pro květiny s výškou větší než určitý počet nebo kvetoucí.
Možnost 15
1. Zobrazte seznam klientů, kteří se ubytovali na pokojích v určeném období.
2. Zobrazte celkovou výši plateb za pokoje pro každého klienta.
3. Zobrazte datum příjezdu, typ pokoje, celé jméno klientů registrovaných v uvedeném období.
4. Zobrazte seznam registrovaných klientů na pokojích určitého typu.
Možnost 16
1. Zobrazte seznam zařízení se zadaným typem.
2. Zobrazte seznam zařízení, které bylo zapůjčeno konkrétním klientem.
3. Zobrazte seznam lidí, kteří si pronajali vybavení, a počet jejich požadavků seřazený podle počtu požadavků v sestupném pořadí.
4. Zobrazte informace o klientech seřazené podle adresy.
Možnost 17
1. Zobrazte seznam cenností, jejichž kupní cena je vyšší než určitá hodnota nebo záruční doba vyšší než zadané číslo.
2. Zobrazte seznam umístění materiálových aktiv, jejichž názvy obsahují zadané slovo.
3. Zobrazte součet hodnot hodnot s kódem v zadaném rozsahu.
4. Zobrazte seznam finančně odpovědných osob s datem vzniku zaměstnání v zadaném rozsahu.
Možnost 18
1. Zobrazte seznam oprav provedených konkrétním technikem.
2. Zobrazte seznam pracovních fází zahrnutých do díla, jehož název obsahuje zadané slovo.
3. Zobrazte součet nákladů na etapy oprav prací pro práci s kódem v zadaném rozsahu.
4. Zobrazte seznam mistrů s datem přijetí v zadaném rozsahu.
Možnost 19
1. Zobrazte seznam léků s konkrétní indikací.
2. Zobrazte seznam čísel účtenek, za které bylo prodáno více než určitý počet léků.
3. Na účtence se zadaným číslem zobrazte datum prodeje, částku, jméno pokladníka a lék.
4. Zobrazte seznam léků a měrných jednotek pro léky, jejichž množství v balení je větší než zadané číslo nebo kód léku menší než určitá hodnota.
Možnost 20
1. Zobrazte seznam zaměstnanců se zadanou pozicí.
2. Zobrazte seznam dokumentů, jejichž obsah obsahuje zadaný fragment slova.
3. Zobrazte datum registrace, typ dokumentu, celé jméno exekutora a skutečnost exekuce u dokumentů evidovaných v uvedeném období.
4. Zobrazte seznam registrovaných dokumentů se zadaným typem dokumentu nebo kódem dokumentu v určitém rozsahu.