mysql რეპლიკაციის დაყენება. რეპლიკაციის საფუძვლები MySQL-ში. რა არის MySQL MASTER SLAVE რეპლიკაცია და რისთვის გამოიყენება?
MySQL სერვერების რეპლიკაციას შედარებით ცოტა ხნის წინ გავეცანი და როცა კონფიგურაციის სხვადასხვა ექსპერიმენტი ჩავატარე, დავწერე ის, რაც გამომივიდა. როდესაც საკმაოდ ბევრი მასალა მოვაგროვე, ამ სტატიის დაწერის იდეა გამიჩნდა. მე შევეცადე შემეგროვებინა რჩევები და გადაწყვეტილებები იმ ძირითადი საკითხების შესახებ, რომლებიც მე შემხვედრია. გზადაგზა მოგაწოდებთ დოკუმენტაციისა და სხვა წყაროების ბმულებს. არ შემიძლია პრეტენზია სრულად აღვწერო, მაგრამ იმედი მაქვს, რომ სტატია სასარგებლო იქნება.
მოკლე შესავალი
რეპლიკაცია (ლათინური რეპლიკიდან - ვიმეორებ) არის მონაცემთა ცვლილებების რეპლიკაცია მონაცემთა ძირითადი სერვერიდან ერთ ან რამდენიმე დამოკიდებულ სერვერზე. ჩვენ დავურეკავთ მთავარ სერვერს ოსტატიდა დამოკიდებული - ასლები.მონაცემთა ცვლილებები, რომლებიც ხდება მასტერზე, მეორდება რეპლიკებზე (მაგრამ არა პირიქით). ამიტომ, მონაცემების შესაცვლელად (INSERT, UPDATE, DELETE და ა.შ.) მოთხოვნები შესრულებულია მხოლოდ მასტერზე, ხოლო მონაცემების წაკითხვის მოთხოვნა (სხვა სიტყვებით, SELECT) შეიძლება შესრულდეს როგორც რეპლიკაზე, ასევე მთავარზე. რეპლიკაციის პროცესი ერთ-ერთ რეპლიკაზე არ ახდენს გავლენას სხვა რეპლიკების მუშაობაზე და პრაქტიკულად არ მოქმედებს ოსტატის მუშაობაზე.
რეპლიკაცია ხორციელდება ორობითი ჟურნალების გამოყენებით, რომლებიც ინახება მასტერზე. ისინი ინახავენ ყველა მოთხოვნას, რომელიც იწვევს (ან პოტენციურად იწვევს) მონაცემთა ბაზაში ცვლილებებს (შეკითხვები არ არის შენახული აშკარად, ასე რომ, თუ გსურთ მათი ნახვა, მოგიწევთ გამოიყენოთ mysqlbinlog პროგრამა). ბინლოგები გადადის რეპლიკებზე (მასტერიდან გადმოწერილ ბინლოგს ეწოდება "რელეი ბინლოგი") და შენახული მოთხოვნები სრულდება გარკვეული პოზიციიდან დაწყებული. მნიშვნელოვანია გვესმოდეს, რომ რეპლიკაციის დროს გადადის არა თავად შეცვლილი მონაცემები, არამედ მხოლოდ მოთხოვნები, რომლებიც იწვევს ცვლილებებს.
რეპლიკაციის დროს, მონაცემთა ბაზის შინაარსი დუბლირებულია რამდენიმე სერვერზე. რატომ არის საჭირო დუბლირების გამოყენება? არსებობს რამდენიმე მიზეზი:
- შესრულება და მასშტაბურობა. ერთმა სერვერმა შეიძლება ვერ გაუმკლავდეს მონაცემთა ბაზაში წაკითხვისა და ჩაწერის ერთდროული ოპერაციებით გამოწვეულ დატვირთვას. რეპლიკების შექმნის სარგებელი უფრო დიდი იქნება, რაც უფრო მეტი წაკითხვა გაქვთ ერთ ჩანაწერზე თქვენს სისტემაში.
- შეცდომის ტოლერანტობა. რეპლიკის წარუმატებლობის შემთხვევაში, წაკითხვის ყველა მოთხოვნა შეიძლება უსაფრთხოდ გადაეცეს მასტერს. თუ მასტერი ვერ მოხერხდება, ჩაწერის მოთხოვნები შეიძლება გადავიდეს რეპლიკაზე (მასტერის აღდგენის შემდეგ, მას შეუძლია მიიღოს რეპლიკას როლი).
- მონაცემთა სარეზერვო. რეპლიკა შეიძლება „შეანელოს“ გარკვეული ხნით mysqldump-ის შესასრულებლად, მაგრამ მასტერს არ შეუძლია.
- გადავადებული გამოთვლები. მძიმე და ნელი SQL მოთხოვნები შეიძლება შესრულდეს ცალკეულ რეპლიკაზე, მთელი სისტემის ნორმალურ მუშაობაში ჩარევის შიშის გარეშე.
რეპლიკაციის დაყენება
ვთქვათ, გვაქვს სამუშაო MySQL მონაცემთა ბაზა, უკვე შევსებული მონაცემებით და ჩართული. და ზემოთ აღწერილი ერთ-ერთი მიზეზის გამო, ჩვენ ვაპირებთ გავააქტიუროთ ჩვენი სერვერის რეპლიკაცია. ჩვენი საწყისი მონაცემები:- მთავარი IP მისამართია 192.168.1.101, რეპლიკა არის 192.168.1.102.
- MySQL დაინსტალირებული და კონფიგურირებულია
- თქვენ უნდა დააკონფიგურიროთ testdb მონაცემთა ბაზის რეპლიკაცია
- ჩვენ შეგვიძლია ცოტა ხნით გავაჩეროთ ოსტატი
- ჩვენ რა თქმა უნდა გვაქვს root ორივე მანქანაზე
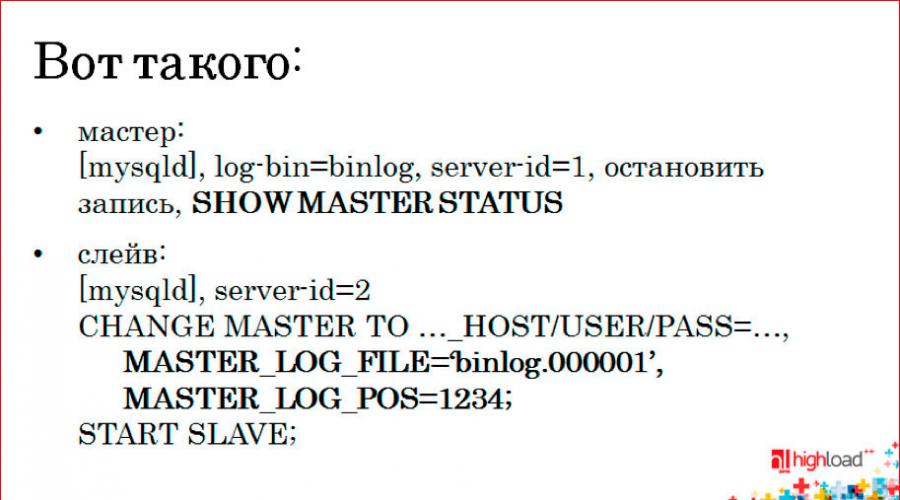
ოსტატის პარამეტრები
დარწმუნდით, რომ მიუთითეთ უნიკალური სერვერის ID, ბილიკი ბინარული ჟურნალებისთვის და მონაცემთა ბაზის სახელი რეპლიკაციისთვის განყოფილებაში:სერვერის ID = 1
log-bin = /var/lib/mysql/mysql-bin
replicate-do-db = testdb
დარწმუნდით, რომ გაქვთ საკმარისი ადგილი დისკზე ორობითი ჟურნალებისთვის.
დავამატოთ რეპლიკაციის მომხმარებელი, რომლის უფლებებითაც განხორციელდება რეპლიკაცია. "რეპლიკაციის მონა" პრივილეგია საკმარისი იქნება:
mysql@master> GRANT replication slave ON "testdb".* "replication"@"192.168.1.102" იდენტიფიცირებული "პაროლით";
გადატვირთეთ MySQL, რომ კონფიგურაციის ცვლილებები ძალაში შევიდეს:
root@master# სერვისი mysqld გადატვირთეთ
თუ ყველაფერი კარგად წავიდა, "show master status" ბრძანება უნდა აჩვენოს მსგავსი რამ:
mysql@master>მასტერის სტატუსის ჩვენება\G
ფაილი: mysql-bin.000003
პოზიცია: 98
Binlog_Do_DB:
Binlog_Ignore_DB:
პოზიციის მნიშვნელობა უნდა გაიზარდოს მასტერზე მონაცემთა ბაზაში ცვლილებების შეტანისას.
რეპლიკა პარამეტრები
მოდით, კონფიგურაციის განყოფილებაში დავაკონკრეტოთ სერვერის ID, მონაცემთა ბაზის სახელი და რელე ბილოგების გზა, შემდეგ გადატვირთოთ MySQL:სერვერის ID = 2
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = testdb
Root@replica# სერვისის mysqld გადატვირთვა
მონაცემთა გადაცემა
აქ მოგვიწევს მონაცემთა ბაზის ჩაკეტვა ჩასაწერად. ამისათვის შეგიძლიათ ან შეაჩეროთ აპლიკაციები, ან გამოიყენოთ მხოლოდ read_ly დროშა მასტერზე (ყურადღება: ეს დროშა არ მოქმედებს SUPER პრივილეგიის მქონე მომხმარებლებზე). თუ ჩვენ გვაქვს MyISAM ცხრილები, მოდით ასევე "გარეცხოთ ცხრილები":mysql@master> FLUSH TABLES WITH READ LOCK;
mysql@master> SET GLOBAL read_only = ON;
მოდით ვნახოთ ოსტატის სტატუსი ბრძანებით "მასტერ სტატუსის ჩვენება" და გავიხსენოთ File და Position მნიშვნელობები (მაგისტრის წარმატებით დაბლოკვის შემდეგ, ისინი არ უნდა შეიცვალოს):
ფაილი: mysql-bin.000003
პოზიცია: 98
ჩვენ ვაყრით მონაცემთა ბაზას და ოპერაციის დასრულების შემდეგ ვხსნით ოსტატის საკეტს:
mysql@master> SET GLOBAL read_only = OFF;
ჩვენ გადავცემთ ნაგავსაყრელს რეპლიკაში და აღადგენს მონაცემებს მისგან.
დაბოლოს, ჩვენ ვიწყებთ რეპლიკაციას ბრძანებებით "change master to" და "start slave" და ვნახოთ ყველაფერი კარგად იყო თუ არა:
mysql@replica> CHANGE MASTER TO MASTER_HOST = "192.168.1.101", MASTER_USER = "რეპლიკაცია", MASTER_PASSWORD = "პაროლი", MASTER_LOG_FILE = "mysql-bin.000003", MASTER_98;
mysql@replica> start slave;
ჩვენ ვიღებთ MASTER_LOG_FILE და MASTER_LOG_POS მნიშვნელობებს მასტერისგან.
ვნახოთ, როგორ მიდის რეპლიკაცია ბრძანებით "Show Slave status":
mysql@replica> SLAVE STATUS-ის ჩვენება\G
Slave_IO_State: ელოდება მასტერს ღონისძიების გაგზავნას
Master_Host: 192.168.1.101
Master_User: რეპლიკაცია
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 98
Relay_Log_File: mysql-relay-bin.001152
Relay_Log_Pos: 235
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: დიახ
Slave_SQL_Running: დიახ
Replicate_Do_DB: testdb,testdb
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 98
Relay_Log_space: 235
Until_Condition: არანაირი
სანამ_Log_File:
სანამ_Log_Pos: 0
Master_SSL_Allowed: არა
Master_SSL_CA_ფაილი:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_შიფრა:
Master_SSL_Key:
წამები_უკან_ოსტატი: 5
მე გამოვყავი ყველაზე საინტერესო ღირებულებები ახლა. თუ რეპლიკაცია წარმატებით დაიწყო, მათი მნიშვნელობები უნდა იყოს დაახლოებით იგივე, რაც ჩამონათვალში (იხილეთ დოკუმენტაციაში ბრძანების "Show Slave status"-ის აღწერა). Seconds_Behind_Master მნიშვნელობა შეიძლება იყოს ნებისმიერი მთელი რიცხვი.
თუ რეპლიკაცია ნორმალურია, რეპლიკა მიჰყვება მასტერს (ლოგის ნომერი Master_Log_File-ში და Exec_Master_Log_Pos პოზიცია გაიზრდება). რეპლიკის დაგვიანების დრო მასტერისგან (Seconds_Behind_Master), იდეალურად, უნდა იყოს ნულის ტოლი. თუ ის არ მცირდება ან იზრდება, შესაძლებელია, რომ რეპლიკაზე დატვირთვა ძალიან მაღალი იყოს - მას უბრალოდ არ აქვს დრო, რომ გაიმეოროს მასტერზე მომხდარი ცვლილებები.
თუ Slave_IO_State ცარიელია და Seconds_Behind_Master არის NULL, რეპლიკაცია არ დაწყებულა. მიზეზის გასარკვევად იხილეთ MySQL ჟურნალი, აღმოფხვრა და გადატვირთე რეპლიკაცია:
mysql@replica> start slave;
ამ მარტივი ნაბიჯების მეშვეობით ჩვენ ვიღებთ რეპლიკას, რომლის მონაცემები იდენტურია მასტერზე არსებული მონაცემების.
სხვათა შორის, ოსტატის დაბლოკვის დრო არის ნაგავსაყრელის შექმნის დრო. თუ შექმნას მიუღებლად დიდი დრო სჭირდება, შეგიძლიათ სცადოთ ეს:
- დაბლოკეთ მასტერისთვის ჩაწერა read_only დროშით, დაიმახსოვრეთ პოზიცია და შეაჩერეთ MySQL.
- ამის შემდეგ დააკოპირეთ მონაცემთა ბაზის ფაილები რეპლიკაში და ჩართეთ მასტერი.
- დაიწყეთ რეპლიკაცია ჩვეულებრივი გზით.
ასლების დამატება
დავუშვათ, ჩვენ უკვე გვყავს სამუშაო ოსტატი და რეპლიკა და მათ კიდევ ერთი უნდა დავამატოთ. ამის გაკეთება კიდევ უფრო ადვილია, ვიდრე მასტერზე პირველი ასლის დამატება. და რაც უფრო სასიამოვნოა ის, რომ არ არის საჭირო ამისთვის ოსტატის შეჩერება.პირველ რიგში, მოდით დავაკონფიგურიროთ MySQL მეორე რეპლიკაზე და დავრწმუნდეთ, რომ კონფიგურაციაში შევიყვანეთ საჭირო პარამეტრები:
სერვერის ID = 3
replicate-do-db = testdb
ახლა მოდით შევაჩეროთ რეპლიკაცია პირველ რეპლიკაზე:
mysql@replica-1> stop slave;
რეპლიკა ჩვეულ რეჟიმში გააგრძელებს მუშაობას, მაგრამ მასზე არსებული მონაცემები აღარ იქნება აქტუალური. მოდით გადავხედოთ სტატუსს და გავიხსენოთ ძირითადი პოზიცია, რომელსაც რეპლიკა მიაღწია რეპლიკაციის შეწყვეტამდე:
mysql@replica-1> SLAVE STATUS-ის ჩვენება\G
ჩვენ გვჭირდება მნიშვნელობები: Master_Log_File და Exec_Master_Log_Pos:
Master_Log_File: mysql-bin.000004
Exec_Master_Log_Pos: 155
მოდით შევქმნათ მონაცემთა ბაზის ნაგავსაყრელი და გავაგრძელოთ რეპლიკაცია პირველ რეპლიკაზე:
mysql@replica-1> START SLAVE;
მოდით აღვადგინოთ მონაცემები ნაგავსაყრელიდან მეორე რეპლიკაზე. შემდეგ ჩართეთ რეპლიკაცია:
mysql@replica-2> CHANGE MASTER TO MASTER_HOST = "192.168.1.101", MASTER_USER = "გამეორება", MASTER_PASSWORD = "პაროლი", MASTER_LOG_FILE = "mysql-bin.000004", MASTER = 5 POSTER
mysql@replica-2> START SLAVE;
MASTER_LOG_FILE და MASTER_LOG_POS მნიშვნელობები არის Master_Log_File და Exec_Master_Log_Pos მნიშვნელობები, შესაბამისად, პირველ რეპლიკაზე ბრძანების "Show Slave status"-ის შედეგიდან.
რეპლიკაცია უნდა დაიწყოს იმ პოზიციიდან, სადაც პირველი რეპლიკა შეჩერდა (და, შესაბამისად, იქმნება ნაგავსაყრელი). ამრიგად, ჩვენ გვექნება ორი ასლი იდენტური მონაცემებით.
რეპლიკების გაერთიანება
ზოგჯერ წარმოიქმნება შემდეგი სიტუაცია: მასტერზე არის ორი მონაცემთა ბაზა, რომელთაგან ერთი იმეორებს ერთ რეპლიკაზე, ხოლო მეორე მეორეზე. როგორ დავაყენოთ ორი მონაცემთა ბაზის რეპლიკაცია ორივე რეპლიკაზე, მასტერზე გადაყრის ან მისი გამორთვის გარეშე? უბრალოდ, ბრძანების "დაიწყე მონამდე" გამოყენებით.ასე რომ, ჩვენ გვყავს ოსტატი მონაცემთა ბაზებით testdb1 და testdb2, რომლებიც რეპლიკირებულია რეპლიკა-1 და რეპლიკა-2, შესაბამისად. მოდით დავაკონფიგურიროთ ორივე მონაცემთა ბაზის რეპლიკაცია replica-1-ზე Master-ის შეჩერების გარეშე.
შეაჩერე რეპლიკაცია replica-2-ზე ბრძანებით და დაიმახსოვრე ოსტატის პოზიცია:
mysql@replica-2> STOP SLAVE;
mysql@replica-2> SLAVE STATUS-ის ჩვენება\G
Master_Log_File: mysql-bin.000015
Exec_Master_Log_Pos: 231
მოდით შევქმნათ testdb2 მონაცემთა ბაზის ნაგავსაყრელი და განვაახლოთ რეპლიკაცია (ეს ასრულებს მანიპულაციებს replica-2-ით). ჩვენ აღვადგენთ ნაგავსაყრელს რეპლიკა-1-ს.
სიტუაცია replica-1-ზე ასეთია: testdb1 მონაცემთა ბაზა არის ერთ მთავარ პოზიციაზე და აგრძელებს რეპლიკაციას, testdb2 მონაცემთა ბაზა აღდგენილია ნაგავსაყრელიდან სხვა პოზიციიდან. მოდით გავაერთიანოთ ისინი.
მოდით შევაჩეროთ რეპლიკაცია და გავიხსენოთ ოსტატის პოზიცია:
mysql@replica-1> STOP SLAVE;
mysql@replica-1> SLAVE STATUS-ის ჩვენება\G
Exec_Master_Log_Pos: 501
მოდით დავრწმუნდეთ, რომ რეპლიკა-1-ის კონფიგურაციაში მეორე მონაცემთა ბაზის სახელი მითითებულია განყოფილებაში:
replicate-do-db = testdb2
მოდით გადატვირთოთ MySQL, რათა კონფიგურაციის ცვლილებები ძალაში შევიდეს. სხვათა შორის, შესაძლებელი იყო უბრალოდ გადატვირთვა MySQL რეპლიკაციის შეჩერების გარეშე - ჟურნალიდან გავიგებდით, რომელ პოზიციაზე შეჩერდა მასტერში რეპლიკაცია.
ახლა მოდით გავიმეოროთ პოზიციიდან, სადაც replica-2 იყო შეჩერებული, იმ პოზიციამდე, სადაც ჩვენ უბრალოდ შევაჩერეთ რეპლიკაცია:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101", MASTER_USER = "რეპლიკაცია", MASTER_PASSWORD = "პაროლი", MASTER_LOG_FILE = "mysql-bin.000015", MASTER_1.
mysql@replica-1> დაწყება slave სანამ MASTER_LOG_FILE = "mysql-bin.000016 ", MASTER_LOG_POS = 501;
რეპლიკაცია დასრულდება როგორც კი რეპლიკა მიაღწევს მითითებულ პოზიციას განყოფილებაში სანამ, რის შემდეგაც ჩვენი ორივე მონაცემთა ბაზა შეესაბამება იმავე მთავარ პოზიციას (რომელზეც ჩვენ შევაჩერეთ რეპლიკაცია replica-1-ზე). მოდით დავრწმუნდეთ ამაში:
mysql@replica-1> SLAVE STATUS-ის ჩვენება\G
mysql@replica-1> START SLAVE;
Master_Log_File: mysql-bin.000016
Exec_Master_Log_Pos: 501
მოდით დავამატოთ ორივე მონაცემთა ბაზის სახელები კონფიგურაციაში replica-1 განყოფილებაში:
replicate-do-db = testdb1
replicate-do-db = testdb2
მნიშვნელოვანია: თითოეული მონაცემთა ბაზა უნდა იყოს ჩამოთვლილი ცალკე ხაზზე.
გადატვირთეთ MySQL და გააგრძელეთ რეპლიკაცია:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101", MASTER_USER = "რეპლიკაცია", MASTER_PASSWORD = "პაროლი", MASTER_LOG_FILE = "mysql-bin.000016", MASTER_1.
მას შემდეგ, რაც replica-1 დაემთხვევა მასტერს, მათი მონაცემთა ბაზის შინაარსი იდენტური იქნება. შეგიძლიათ მონაცემთა ბაზის შერწყმა replica-2-ზე ან ანალოგიურად, ან replica-1-ის სრული ნაგავსაყრელის შედგენით.
კასტინგის ოსტატი და რეპლიკა
შესაძლოა საჭირო გახდეს ასლის გადართვა სამაგისტრო რეჟიმში, მაგალითად, ძირითადი მარცხის შემთხვევაში ან მასზე ტექნიკური სამუშაოების შესრულებისას. იმისათვის, რომ ასეთი გადართვა შესაძლებელი გახდეს, თქვენ უნდა დააკონფიგურიროთ რეპლიკა, როგორც მასტერი, ან გააკეთოთ ის პასიური ოსტატი.მოდით გავააქტიუროთ ორობითი ჟურნალი (გარდა სარელეო ბილოგებისა) კონფიგურაციაში განყოფილებაში:
log-bin = /var/lib/mysql/mysql-bin
და დაამატეთ მომხმარებელი რეპლიკაციისთვის:
mysql@master> GRANT replication slave ON 'testdb'.* to 'replication'@'192.168.1.101′ იდენტიფიცირებული "პაროლით";
პასიური მასტერი ახორციელებს რეპლიკაციას, როგორც ჩვეულებრივი რეპლიკა, მაგრამ გარდა ამისა ის ქმნის ორობით ლოგიებს - ანუ ჩვენ შეგვიძლია დავიწყოთ რეპლიკაცია მისგან. მოდით გადავამოწმოთ ეს ბრძანებით "მასტერ სტატუსის ჩვენება":
mysql@replica> სამაგისტრო სტატუსის ჩვენება\G
ფაილი: mysql-bin.000001
პოზიცია: 61
Binlog_Do_DB:
Binlog_Ignore_DB:
ახლა, პასიური მასტერის აქტიურ რეჟიმში გადასართავად, თქვენ უნდა შეაჩეროთ მასზე რეპლიკაცია და ჩართოთ რეპლიკაცია ყოფილ აქტიურ მასტერზე. იმის უზრუნველსაყოფად, რომ მონაცემები არ დაიკარგება გადართვის დროს, აქტიური ოსტატიჩაწერით უნდა იყოს დაბლოკილი.
mysql@master> FLUSH TABLES WITH READ LOCK
mysql@master> SET GLOBAL read_only = ON;
mysql@replica> STOP SLAVE;
mysql@replica> სამაგისტრო სტატუსის ჩვენება;
ფაილი: mysql-bin.000001
პოზიცია: 61
mysql@master> CHANGE MASTER TO MASTER_HOST = "192.168.1.102", MASTER_USER = "რეპლიკაცია", MASTER_PASSWORD = "პაროლი", MASTER_LOG_FILE = "mysql-bin.000001", MASTER_LOG1;
mysql@master> start slave;
ეს არის ის, ასე რომ, ჩვენ შევცვალეთ აქტიური ოსტატი. თქვენ შეგიძლიათ ამოიღოთ ბლოკი ყოფილი ოსტატისგან.
დასკვნა
ჩვენ ვისწავლეთ ცოტა რამ, თუ როგორ დავაყენოთ რეპლიკაცია MySQL-ში და შევასრულოთ რამდენიმე ძირითადი ოპერაცია. სამწუხაროდ, შემდეგი მნიშვნელოვანი კითხვები რჩება ამ სტატიის ფარგლებს გარეთ:
- წარუმატებლობის ცალკეული წერტილების აღმოფხვრა (SPF, Single Points of Failure). ერთი MySQL სერვერის გამოყენებისას, მისმა წარუმატებლობამ გამოიწვია მთელი სისტემის მარცხი. მრავალი სერვერის გამოყენებისას, რომელიმე მათგანის წარუმატებლობა გამოიწვევს სისტემის უკმარისობას, თუ ჩვენ კონკრეტულად არ ვიზრუნებთ ამაზე. ჩვენ უნდა უზრუნველვყოთ სიტუაციის დამუშავება მასტერისა და რეპლიკას მარცხით. ერთ-ერთი არსებული ინსტრუმენტია MMM, თუმცა ის საჭიროებს მოდიფიკაციას ფაილით.
- დატვირთვის დაბალანსება. მრავალჯერადი რეპლიკების გამოყენებისას ჩვენ გვსურს გამოვიყენოთ გამჭვირვალე დაბალანსების მექანიზმი, განსაკუთრებით იმ შემთხვევაში, თუ რეპლიკების შესრულება არათანაბარია. Linux-ის პირობებში შესაძლებელია სტანდარტული გადაწყვეტის - LVS-ის გამოყენება.
- აპლიკაციის ლოგიკის შეცვლა. იდეალურ სიტუაციაში, მონაცემების წაკითხვის მოთხოვნა უნდა გაიგზავნოს რეპლიკაზე, ხოლო მონაცემების შეცვლის მოთხოვნა უნდა გაეგზავნოს მასტერს. თუმცა, რეპლიკების შესაძლო ჩამორჩენის გამო, ასეთი სქემა ხშირად არაეფექტურია და აუცილებელია ისეთი წაკითხვის მოთხოვნების იდენტიფიცირება, რომლებიც ჯერ კიდევ უნდა შესრულდეს მასტერზე.
გმადლობთ ყურადღებისთვის!
ტეგები: ტეგების დამატება
ცოტა ხნის წინ მთხოვეს საუბარი რეპლიკაცია MySQL-ში. გადავწყვიტე, რომ ეს თემა ბევრს გამოადგება, ამიტომ ამ სტატიაში ვისაუბრებ რა არის რეპლიკაცია MySQL-ში, როდის არის საჭირო და როგორ დავაკონფიგურიროთ იგი.
რეპლიკაციის მთავარი ამოცანაა აერთიანებს რამდენიმე სერვერის ძალას. დავუშვათ, თქვენს ვებსაიტს აქვს გამოყოფილი სერვერი, მაგრამ დროთა განმავლობაში ის ძალიან მონახულებული ხდება და ვეღარ უძლებს დატვირთვას. შედეგად, სერვერი იწყებს რეგულარულად შენელებას და ავარიას. უმარტივესი გზაა უფრო ძლიერი სერვერის ყიდვა და ეს არის ის, რასაც ადამიანების უმეტესობა აკეთებს. მაგრამ ადრე თუ გვიან დგება დრო, როდესაც სერვერის ფასის გაზრდის ღირებულება არ შეესაბამება მისი მუშაობის ზრდას, ამიტომ უფრო მომგებიანია ყიდვა 2 სხვადასხვა სერვერები ნაკლებ ფულზე.
შედეგად, თქვენი მონაცემთა ბაზა ერთდროულად ორ სერვერზე იქნება. როდესაც ერთი მთავარი სერვერი (ანუ მთავარი სერვერი) ვეღარ უმკლავდება, ის გადადის სათადარიგოზე.
ყველა მონაცემთა ბაზის განახლების მოთხოვნა ყოველთვის მიდის მთავარ სერვერზე. მთავარი სერვერის განახლების შემდეგ ის ათავსებს ინფორმაციას ამის შესახებ ცალკე ფაილში, საიდანაც სლავი სერვერები იღებენ ყველა ინფორმაციას. მაგრამ შერჩევის ოპერაციები, რომლებიც, როგორც წესი, უმეტესობაა და ისინი ყველაზე ნელია, უკვე შეიძლება გადავიდეს მონ სერვერებზე, რადგან მონაცემები ორივეში ერთნაირია.
ახლა მოდით გავარკვიოთ როგორ დავაკონფიგურიროთ რეპლიკაცია MySQL-ში:
- დააინსტალირეთ ყველაზე მეტი MySQL-ის უახლესი ვერსიებიყველა სერვერზე.
- შექმენით მომხმარებელი პრივილეგიით მთავარ სერვერზე SLAVE-ის შეცვლა. მისამართისთვის, საიდანაც მას შეუძლია დაკავშირება, მიუთითეთ " ყველა".
- შეაჩერე ყველა სერვერი.
- პარამეტრებში MySQL(ფაილში my.cnf) განყოფილებაში
დაამატეთ შემდეგი ხაზები: log-bin
server-id=1 გთხოვთ გაითვალისწინოთ, რომ სერვერის IDუნდა იყოს განსხვავებული ყველა სერვერზე. სინამდვილეში, ეს არის ის, რაც განასხვავებს ერთ სერვერს მეორისგან. - Slave სერვერებზე დაამატეთ პარამეტრებს MySQLშემდეგი ხაზები: master-host=master_host_name
master-user=შექმნილი_მომხმარებლის შესვლა
master-password= შექმნილი_მომხმარებლის პაროლი
master-port=პორტი_მასტერ_სერვერთან_დაკავშირებისთვის
server-id=id_of_this_slave_server - გადაიტანეთ ყველა ბაზამთავარი სერვერიდან მონებამდე.
- გაიქეციმთავარი სერვერი, შემდეგ ყველა მონა.
რეპლიკაცია- ტექნიკა, რომელიც გამოიყენება დატვირთვის ქვეშ მოქმედი სისტემების არქიტექტურაში, რომლის შედეგია დატვირთვის განაწილება ერთ მონაცემთა ბაზასთან მუშაობისას რამდენიმე სერვერზე. MySQL MASTER SLAVE რეპლიკაცია უფრო ხშირად გამოიყენება, მაგრამ ასევე გამოიყენება მეორე ტიპის რეპლიკაცია - Master-Master.
რა არის MySQL MASTER SLAVE რეპლიკაცია და რისთვის გამოიყენება?
რეპლიკაცია ბატონ-მონამოიცავს მონაცემების დუბლირებას მონურ MySQL სერვერზე, ასეთი დუბლირება ხორციელდება ძირითადად საიმედოობის უზრუნველსაყოფად. თუ Master სერვერი ვერ ხერხდება, მისი ფუნქციები გადადის Slave-ზე.
რეპლიკაცია ასევე შეიძლება განხორციელდეს სისტემის მუშაობის გასაუმჯობესებლად, მაგრამ შესრულება აქ თითქმის ყოველთვის მეორეხარისხოვანია.
როდესაც აპლიკაცია მუშაობს მონაცემთა ბაზასთან, ყველაზე ხშირი ოპერაციებია აირჩიეთ- ითხოვს მონაცემების წაკითხვას, მონაცემების შეცვლას - მოითხოვს წაშლა, INSERT, განახლება, ALTERსტატისტიკურად ეს გაცილებით იშვიათად ხდება.
მონაცემთა დაკარგვის თავიდან ასაცილებლად, თუ რომელიმე სერვერი ვერ ხერხდება, ცხრილებში ინფორმაციის შეცვლის ოპერაციები ყოველთვის მუშავდება Master სერვერის მიერ. შემდეგ ცვლილებები განმეორდება Slave-ზე. კითხვა შეიძლება გაკეთდეს სერვერიდან, რომელიც ასრულებს Slave-ს როლს.
ამის გამო, საიმედოობასთან ერთად შეგიძლიათ მიიღოთ ეფექტურობის მატება.
გამოსავალი პოპულარულია, მაგრამ ყოველთვის არ გამოიყენება, რადგან რეპლიკაციის დროს შეიძლება იყოს შეფერხებები - თუ ეს მოხდება, ინფორმაცია ასევე უნდა წაიკითხოს Master სერვერიდან.
გარკვეული ტიპის მოთხოვნების მიმართვა მონაცემთა ბაზის კონკრეტულ სერვერზე ნებისმიერ შემთხვევაში ხორციელდება აპლიკაციის დონეზე.
თუ თქვენ გამოყოფთ SELECT შეკითხვებს და ყველა სხვას პროგრამის დონეზე, გაგზავნით მათ სასურველ სერვერზე, როდესაც ერთ-ერთი მათგანი ვერ მოხერხდება, პროგრამა, რომელსაც ინფრასტრუქტურა ემსახურება, უფუნქციო იქნება. იმისათვის, რომ ეს იმუშაოს, თქვენ უნდა მიაწოდოთ უფრო რთული სქემა და დაჯავშნოთ თითოეული სერვერი.
რეპლიკაცია არის შეცდომის ტოლერანტობისთვის და არა სკალირების მიზნით.
MySQL MASTER SLAVE რეპლიკაცია - დაყენება Debian-ზე
ჩვენ გამოვიყენებთ ორ სერვერს მისამართებით:
- ძირითადი სერვერი 192.168.0.1
- მონა სერვერი 192.168.0.2
დემონსტრირებისთვის გამოიყენება ლოკალურ ქსელთან დაკავშირებული VDS.
იმისათვის, რომ ყოველთვის ზუსტად ვიცოდეთ, რომელ სერვერზე ვასრულებთ ამა თუ იმ ბრძანებას, ორივე სერვერზე დავარედაქტირებთ /etc/hosts ფაილებს.
192.168.0.1 ოსტატი
192.168.0.2 მონა
მოდით შევცვალოთ არსებული მნიშვნელობები /etc/hostname-ში, შესაბამისად master და slave, რათა ცვლილებები ამოქმედდეს და გადატვირთოთ სერვერი.
1. ჩვენ ვაკეთებთ პარამეტრებს მთავარ სერვერზე.
root@master:/#
მონაცემთა ბაზის სერვერის ძირითადი კონფიგურაციის ფაილის რედაქტირება
mcedit /etc/mysql/my.cnf
აირჩიეთ სერვერის ID - შეგიძლიათ მიუთითოთ ნებისმიერი ნომერი, ნაგულისხმევი არის 1 - უბრალოდ გააუქმეთ ხაზი
სერვერის ID = 1
დააყენეთ ბილიკი ორობითი ჟურნალისკენ - ასევე მითითებულია ნაგულისხმევად, გააუქმეთ კომენტარი
დააყენეთ მონაცემთა ბაზის სახელი, რომელსაც ჩვენ სხვა სერვერზე გავამეორებთ
binlog_do_db = db1
გადატვირთეთ Mysql ისე, რომ კონფიგურაციის ფაილი ხელახლა წაიკითხოს და ცვლილებები ძალაში შევიდეს:
/etc/init.d/mysql გადატვირთვა
2. დააყენეთ მომხმარებლის აუცილებელი უფლებები
გადადით მონაცემთა ბაზის სერვერის კონსოლზე:
ჩვენ ვაძლევთ მომხმარებელს სლავურ სერვერზე საჭირო უფლებებს:
მინიჭეთ გამეორება SLAVE-ზე *.* "slave_user"@"%"-ზე, რომელიც იდენტიფიცირებულია "123"-ით;
მონაცემთა ბაზაში ყველა ცხრილის ჩაკეტვა
FLUSH მაგიდები READ LOCK-ით;
Master სერვერის სტატუსის შემოწმება:
+——————+———-+—————+——————+
| ფაილი | პოზიცია | Binlog_Do_DB | Binlog_Ignore_DB |
+——————+———-+—————+——————+
| mysql-bin.000001 | 327 | db1 | |
+——————+———-+—————+——————+
1 მწკრივი კომპლექტში (0.00 წმ)
3. შექმენით მონაცემთა ბაზის ნაგავსაყრელი სერვერზე
შექმენით მონაცემთა ბაზის ნაგავსაყრელი:
mysqldump -u root -p db1 > db1.sql
განბლოკეთ ცხრილები mysql კონსოლში:
4. მონაცემთა ბაზის ნაგავსაყრელის გადატანა Slave სერვერზე
scp db1.sql [ელფოსტა დაცულია]:/სახლი
ჩვენ ვახორციელებთ შემდგომ მოქმედებებს Slave სერვერზე
root@slave:/#
5. მონაცემთა ბაზის შექმნა
ნაგავსაყრელის ჩატვირთვა:
mysql -u root -p db1< db1.sql
6. ცვლილებების შეტანა my.cnf-ში
mcedit /etc/mysql/my.cnf
ჩვენ ვანიჭებთ ID-ს Master სერვერზე მითითებული მნიშვნელობის გაზრდით
სერვერის ID = 2
დააყენეთ გზა სარელეო ჟურნალისკენ
relay-log = /var/log/mysql/mysql-relay-bin.log
და ბილიკის ჟურნალის გზა Master სერვერზე
log_bin = /var/log/mysql/mysql-bin.log
მიუთითეთ ბაზა
binlog_do_db = db1
სერვისის გადატვირთვა
/etc/init.d/mysql გადატვირთვა
7. დააყენეთ კავშირი Master სერვერთან
CHANGE MASTER TO MASTER_HOST="192.168.0.1", MASTER_USER="slave_user", MASTER_PASSWORD="123", MASTER_LOG_FILE = "mysql-bin.000001", MASTER_LOG_POS = 327;
ჩვენ ვიწყებთ რეპლიკაციას მონა სერვერზე:
თქვენ შეგიძლიათ შეამოწმოთ რეპლიკაციის მოქმედება Slave-ზე შემდეგი მოთხოვნით:
****************************** 1. რიგი ******************** ******
Slave_IO_State: ელოდება მასტერს ღონისძიების გაგზავნას
Master_Host: 192.168.0.1
Master_User: slave_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 107
Relay_Log_File: mysql-relay-bin.000003
Relay_Log_Pos: 253
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: დიახ
Slave_SQL_Running: დიახ
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 107
Relay_Log_Space: 555
სანამ_მდგომარეობა: არცერთი
სანამ_Log_File:
სანამ_Log_Pos: 0
Master_SSL_Allowed: არა
Master_SSL_CA_ფაილი:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_შიფრა:
Master_SSL_Key:
წამები_უკან_ოსტატი: 0
Master_SSL_Verify_Server_Cert: არა
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 მწკრივი კომპლექტში (0.00 წმ)
იმის გამო, რომ შეცდომები არ მომხდარა, შეგვიძლია დავასკვნათ, რომ რეპლიკაცია სწორად არის კონფიგურირებული.
ეს არის კარგი სკალირების ინსტრუმენტი, მაგრამ მისი მთავარი მინუსი არის მონაცემთა კოპირების დესინქრონიზაცია და შეფერხებები, რაც შეიძლება იყოს კრიტიკული.
უფრო თანამედროვე გადაწყვეტის გამოყენება საშუალებას გაძლევთ მთლიანად თავიდან აიცილოთ ისინი. ადვილია დაყენება, საიმედო და გამორიცხავს მონაცემთა ბაზის ნაგავსაყრელის ხელით კოპირების აუცილებლობას.
ჩემი მოხსენება განკუთვნილია იმ ადამიანებისთვის, რომლებმაც იციან სიტყვა "რეპლიკაცია", იციან კიდეც, რომ MySQL აქვს და ალბათ ერთხელ დააყენეს, დახარჯეს 15 წუთი და დაივიწყეს. სხვა არაფერი იციან მის შესახებ.
ანგარიში არ შეიცავს:

ეს ყველაფერი ინტერნეტშია, სინტაქსის გაგებას აზრი არ აქვს.
ჩვენ ცოტათი გავივლით თეორიას, ვეცდებით აგიხსნათ, როგორ მუშაობს ეს ყველაფერი შიგნით და ამის შემდეგ შეგიძლიათ თავად ჩაყვინთოთ დოკუმენტაციაში სამმაგი ძალით.
რა არის რეპლიკაცია, პრინციპში? ეს არის ცვლილებების კოპირება. ჩვენ გვაქვს მონაცემთა ბაზის ერთი ასლი, გვინდა სხვა ასლი რაღაც მიზნით.
რეპლიკაცია მოდის სხვადასხვა ტიპის. შედარების სხვადასხვა ღერძი:
- ცვლილებების სინქრონიზაციის ხარისხი (სინქრონიზაცია, ასინქრონიზაცია, ნახევრადსინქრონიზაცია);
- ჩამწერი სერვერების რაოდენობა (M/S, M/M);
- ფორმატის შეცვლა (განცხადებაზე დაფუძნებული (SBR), მწკრივზე დაფუძნებული (RBR), შერეული);
- თეორიულად, ცვლილებების გადაცემის მოდელი (ბიძგი, დახევა).
სახალისო ფაქტი - თუ ცოტას დაფიქრდებით, რეპლიკაცია თეორიულად გვეხმარება მხოლოდ კითხვის მასშტაბირებაში ფუნდამენტური მიზეზების გამო. აქ არის გარკვეულწილად არა აშკარა დასკვნა. ეს იმიტომ ხდება, რომ თუ ჩვენ გვჭირდება გარკვეული რაოდენობის ცვლილებების ატვირთვა მონაცემთა იმავე ასლზე და მონაცემთა ამ კონკრეტულ ასლს ემსახურება ერთი და იგივე სერვერი, მაშინ ამ სერვერს შეუძლია გაუძლოს განახლებების გარკვეულ რაოდენობას წამში და არა მეტი იქ აიტვირთება. სერვერს შეუძლია წამში 1000 ჩანაწერის განახლება, მაგრამ არა 2000. რა შეიცვლება, თუ ამ სერვერზე დააყენებთ ასლს, არ აქვს მნიშვნელობა master-slave ან master-master რეჟიმში? შეძლებთ ამ რეპლიკაზე მეორე ათასი განახლების გადატანას? სწორი პასუხია არა.
რა თქმა უნდა, თქვენ შეგიძლიათ დაამატოთ დამატებითი განახლებები რეპლიკას მასტერ-მასტერ რეჟიმში, მაგრამ სხვა საქმეა, რომ როდესაც ისინი არ მიდიან პირველ მასტერზე და ცდილობენ მასზე მეორე ათასი განახლების გაკეთებას, მოცულობა აღარ იქნება საკმარისი. . თქვენ უნდა გესმოდეთ და არ აურიოთ ორი თითქმის აშკარა წერტილი, რომ რეპლიკაცია არის ერთი რამ, მაგრამ რომ მონაცემები უნდა გაიყოს, და თუ თქვენ გჭირდებათ მასშტაბირება არა კითხვაზე, არამედ წერაზე, მაშინ სხვა რამის გაკეთება მოგიწევთ. და რეპლიკაცია ნამდვილად არ დაეხმარება.
იმათ. რეპლიკაცია უფრო კითხვას ეხება.
სინქრონიზაციის შესახებ.
სინქრონიზაცია არის ხელმისაწვდომობისა და ხელმისაწვდომობის გარანტია. ხელმისაწვდომობა იმ გაგებით, რომ ჩვენი ვალდებულება გავიდა, ტრანზაქცია განხორციელდა, ყველაფერი კარგადაა, ეს მონაცემები ჩანს კლასტერში ერთი ან რამდენიმე კვანძისთვის, მათ შეუძლიათ მონაწილეობა მიიღონ შემდეგ მოთხოვნებში. ხელმისაწვდომობა ნიშნავს, რომ მონაცემები, პრინციპში, ერთზე მეტ სერვერზეა, მაგრამ შესაძლოა ტრანზაქცია არ დაიკარგა და არ არის ხელმისაწვდომი.
არ არის "ჩაბარება წარმატებით დასრულდა, რას ნიშნავს აქ თავშეკავება?" სინქრონული ჩადენა ნიშნავს, რომ ჩვენი ლოკალური და დისტანციური (მინიმუმ ერთ რეპლიკაზე) დასრულდა, ე.ი. ჩვენ მივეცით რაღაც მანქანას, თუ გვაქვს სინქრონული რეპლიკაციის რეჟიმი, მაშინ ეს ცვლილებები წარმატებით განხორციელდა, ისინი ხილულია შემდგომი მოთხოვნებისთვის ადგილობრივ მანქანაზე და ასევე ჩანს დისტანციურ მანქანაზე (მინიმუმ ერთი). ეს ნიშნავს, რომ თუ სტანდარტული საგანგებო სიტუაცია მოხდა, ე.ი. ერთ-ერთ სერვერზე გაფრინდა ღილაკი და გაარღვია ყველაფერი - პროცესორიდან თავად ხრახნამდე, შემდეგ, ამის მიუხედავად, მონაცემები არა მხოლოდ კოპირდება გარკვეულ დისტანციურ სერვერზე, არამედ, გარდა ამისა, შეიძლება მყისიერად, ყოველგვარი გარეშე. დამატებითი შეფერხებები, მონაწილეობა მიიღოთ შემდგომ ტრანზაქციებში.
ეს ყველაფერი ზოგადი ტერმინოლოგიაა და აბსოლუტურად არაფერი აქვს საერთო MySQL-თან. ნებისმიერ განაწილებულ სისტემაში ის ასე იქნება მოწყობილი.
ასინქრონული ვალდებულება - დამატებითი გარანტიების გარეშე, თქვენი იღბლიდან გამომდინარე.
ნახევრად სინქრონული დასრულება კარგი შუალედური გამოსავალია, ეს არის მაშინ, როდესაც ჩვენი ლოკალური commit გავიდა, არაფერია ცნობილი დისტანციური დაშვების შესახებ - შესაძლოა მონამ დაიჭირა, ან შეიძლება არა, მაგრამ მაინც მივიღეთ დადასტურება, რომ ეს მონაცემები არის სადღაც გაფრინდნენ და იქ მიიღეს და, ალბათ, მოაწერეს ხელი.
ჩაწერის სერვერების შესახებ. რა არის რეპლიკაციის ტიპები?
Master-slave კლასიკური, ცვლილებები ყველა გადადის ერთ სერვერზე, რის შემდეგაც ისინი კოპირდება ბევრ რეპლიკაზე.
Master-Master true - როდესაც ცვლილებები მიედინება ოსტატების თაიგულზე ერთდროულად და რატომღაც ერთიდან მეორეზე, მეორიდან მესამეზე და მათ შორის ყველა, რაც იწვევს როგორც უამრავ სიხარულს, ასევე უამრავ ავტომატურ პრობლემას. გასაგებია, რომ როდესაც თქვენ გაქვთ ერთი "ოქროს ასლი" და მისგან რამდენიმე ასლი, რომელიც (იდეალურად - მყისიერად) უნდა გაიმეოროს ეს "ოქროს ასლი", მაშინ ყველაფერი შედარებით მარტივია იმ თვალსაზრისით, თუ როგორ უნდა გადაიტანოთ მონაცემები წინ და უკან. და რას აკეთებენ თითოეულ კონკრეტულ ეგზემპლარზე. მასტერ-მასტერთან საინტერესო „თავის ტკივილი“ იწყება და, ხაზს ვუსვამ, არა კონკრეტულად MySQL-ის შემთხვევაში, არამედ წმინდა თეორიულად. რა უნდა გააკეთოს, თუ ერთდროულად ორ კვანძზე ცდილობდნენ ერთი და იგივე ტრანზაქციის განხორციელებას, რაც ცვლის ერთსა და იმავე მონაცემებს და, მაგალითის სიმარტივისთვის, ცვლის მას სხვადასხვა გზით. გასაგებია, რომ ამ ორ ცვლილებას ერთდროულად ვერ გამოვიყენებთ. იმ მომენტში, როდესაც ვიწყებთ რაღაცის შეცვლას ერთ კვანძზე, მეორე კვანძზე ჯერ არაფერია. კონფლიქტი. ერთ-ერთი ტრანზაქცია უნდა დაბრუნდეს. გარდა ამისა, ცალკეული „ცეკვები“ იწყება საათების შემოწმებით და ა.შ.
საინტერესო მომენტი - ის ვარიანტიც კი, სადაც საბოლოო ჯამში ყველა ოსტატის ყველა ცვლილება თანდათან უნდა გავრცელდეს ყველგან, მაინც არ დაეხმარება იმავე ჩაწერის სიჩქარეს. სირცხვილია, მაგრამ ასეა.
მშვენიერი ვარიანტი ჰქვია "Master-slave + routing მოთხოვნები". ეს სასიამოვნოა, რადგან ადვილია პროგრამირება შიგნით, თქვენ გაქვთ ერთი მთავარი ასლი, თქვენ იმეორებთ მას რამდენიმე მანქანაზე. ეს ბევრად უფრო მარტივია, ვიდრე მასტერ-მასტერ გარემოში, როდესაც ყველას აქვს თანაბარი უფლებები და ა.შ., მაგრამ აპლიკაციის თვალსაზრისით მაინც ჩანს, რომ თქვენ გაქვთ ბევრი ჩაწერის წერტილი. თქვენ მოდიხართ ნებისმიერ კვანძში, მან იცის სად გაგიგზავნოთ და წარმატებულად მიგყავართ. ისე, წაკითხვები მასშტაბირებულია - ეს არის გამეორების სიხარული. თქვენ შეგიძლიათ წაიკითხოთ ყველაფერი ყველა წერტილიდან, ყოველთვის.
ახლა უფრო ახლოს არის მონაცემთა ბაზებთან, "ჯადოსნური" განცხადებებზე დაფუძნებული, მწკრივზე დაფუძნებული და ა.შ. ფორმატები. ცვლილებების ფორმატის შესახებ.
რა შეგიძლიათ გააკეთოთ? თქვენ შეგიძლიათ თავად გადასცეთ მოთხოვნები, ან შეგიძლიათ გადასცეთ მხოლოდ შეცვლილი რიგები. ხაზს ვუსვამ, რომ სანამ ჯერ არ ჩავუღრმავდით MySQL-ის ჯუნგლებში, ეს შეიძლება გაკეთდეს ნებისმიერი DBMS-ით, რომელსაც აქვს მოთხოვნები, რომლებიც წარმოქმნიან ცვლილებების დიდ (ან არც თუ ისე დიდ) რაოდენობას, ე.ი. ბევრი მონაცემების განახლება. ჩნდება კითხვა - კონკრეტულად რას ვაკოპირებთ? თქვენ შეგიძლიათ თავად გაგზავნოთ მოთხოვნები კვანძებს შორის, ან შეგიძლიათ გაგზავნოთ მხოლოდ შეცვლილი მონაცემები. საინტერესოა, რომ ორივე გზა ძალიან ცუდია! კვლავ შეგიძლიათ სცადოთ შერევა.
კიდევ ერთი პუნქტი იმის შესახებ, თუ რა ტიპის რეპლიკაციები არსებობს. განაწილების მოდელის შესახებ. ალბათ, სადღაც Push-ზე დაფუძნებული მოდელი ჯერ ბოლომდე არ ჩამკვდარა, როდესაც კვანძი, რომელმაც ცვლილებები შეასრულა, ვალდებულია გაგზავნოს ისინი ყველა სხვა კვანძში. პროგრამირებისა და თვალთვალის მდგომარეობიდან გამომდინარე, ეს ჯერ კიდევ უჭირს, ამიტომაც, ამა თუ იმ კვანძიდან განახლებების მიღება ბევრად უფრო ადვილია, ვიდრე ერთ კვანძზე ქაოტური კასეტურის მონიტორინგი.
დაინერგა რამდენიმე ზოგადი ტერმინი. მოდით გადავიდეთ იმაზე, თუ როგორ გავაკეთეთ ეს MySQL-ში.
MySQL, თავისთავად, ერთგვარი მოტყუებაა. არსებობს ლოგიკური ფენა სახელწოდებით MySQL, რომელიც ეხება ყველა სახის ზოგად ნივთს, რომელიც იზოლირებულია მონაცემთა შენახვისგან - ქსელი, ოპტიმიზატორი, ქეში და ა.შ. კონკრეტული ფიზიკური ფენა, რომელიც პასუხისმგებელია მონაცემთა შენახვაზე, მდებარეობს ერთი სართულის ქვემოთ. არის რამდენიმე ჩაშენებული და ზოგიერთი დაინსტალირებულია დანამატებით. მაგრამ ჩაშენებული MyISAM, InnoDB და ა.შ. ცხოვრობს ფიზიკურ ფენაზე. მოდულის არქიტექტურა მაგარია, შეგიძლიათ აიღოთ ახალი ძრავა, მაგრამ გარკვეული არაოპტიმალურობა მაშინვე ჩნდება. პრინციპში, ტრანზაქციის ჩაწერის წინა ჟურნალი" და (WAL), რომლებსაც ფიზიკური შენახვის ფენა მაინც წერს, კარგი იქნება რეპლიკაციისთვის და თუ სისტემამ იცის, რომ არსებობს გარკვეული ფიზიკური ფენა, ან საკმარისად კარგად არის დაკავშირებული ამ ფიზიკური ფენა, მაშინ შესაძლებელი იქნებოდა არა ცალკე ჟურნალის დაწერა ლოგიკურ დონეზე, არამედ იგივე WAL-ის გამოყენება, მაგრამ MySQL-ით ეს კონცეპტუალურად შეუძლებელია, ან თუ შეცვლით ინტერფეისს PSE-ში ისე, რომ ეს შესაძლებელი გახდეს კონცეპტუალურად. ბევრი სამუშაო იქნება.
რეპლიკაცია ხორციელდება თავად MySQL-ის დონეზე. ამაში ასევე არის კარგი - გარდა ერთი ჟურნალისა, შენახვის ძრავის ღრმად შიდა მონაცემების სახით, არის მეტ-ნაკლებად ლოგიკური ჟურნალი, ალბათ განცხადების დონეზე, რომელიც შენარჩუნებულია ამ ძრავისგან დამოუკიდებლად "დამატებითი" უსაფრთხოება და ა.შ. პლუს, რადგან არ არსებობს შიდა შეზღუდვები, შეგიძლიათ გააკეთოთ ნებისმიერი კრეატიული რამ, როგორიცაა ძრავის გამოცვლა.
ამ თვალსაზრისით, MySQL 4.1 დანერგილია: master-slave, pull-based, მკაცრად ასინქრონული და მკაცრად SBR. თუ თქვენ ჩარჩენილი ხართ ძველ 4.x ეპოქაში, მაშინ ყველაფერი თქვენთვის ცუდია. ვერსიები 5.x უკვე თითქმის 10 წლისაა - განახლების დროა.
სასაცილოა თვალყური ადევნო ვერსიებს, თუ როგორ აბიჯებდნენ ადამიანები ყველანაირ ჭურჭელზე და როცა ვერაფერს გააკეთებდნენ, ახალ თასმებს აყრიდნენ ამ თაიგულებზე, რათა ცხოვრება ასეთი მტკივნეული არ ყოფილიყო. ასე რომ, 5.1 ვერსიაში, RBR დაემატა SBR-ის გარდაუვალი პრობლემების კომპენსაციის მიზნით და დაემატა შერეული რეჟიმი. 5.6 ვერსიაში დავამატეთ კიდევ რამდენიმე სასიამოვნო რამ: ნახევრად სინქრონიზაცია, დაგვიანებული მონა, GTID.
კიდევ ერთი რამ. ვინაიდან MySQL არის ერთგვარი საერთო ფენა, ერთის მხრივ, და ჩამრთველი ძრავების თაიგული, მეორეს მხრივ, ჩაშენებულის ჩათვლით, გარკვეული წერტილიდან არის ღვთაებრივი NDB კლასტერი, რომლის შესახებაც მაგარ რაღაცეებს ამბობენ. არსებობს სრულიად სინქრონული მასტერ-მასტერ რეპლიკაცია, ძალიან ხელმისაწვდომი მეხსიერებაში არსებული მონაცემთა ბაზა... მაგრამ არის ერთი სიფრთხილე - როგორც კი დაიწყებთ ადამიანების ძებნას, რომლებიც იყენებენ NDB კლასტერს წარმოებაში, ასეთი ხალხი ძალიან ცოტაა.
რას აკეთებს მასტერი, როდესაც გადაწყვეტთ რეპლიკაციის ჩართვას? მასტერში საკმაოდ ბევრი დამატებითი მოძრაობა მიმდინარეობს. ჩვეულებისამებრ, ჩვენ ვიღებთ მოთხოვნებს ქსელში, ვაანალიზებთ მათ, ვაგზავნით ტრანზაქციებს, ჩავწერთ მათ და ა.შ. ამის გარდა, ლოგიკურ დონეზე, MySQL ოსტატი იწყებს ბინარული ჟურნალის შენარჩუნებას - ფაილი, არა საკმაოდ ტექსტური, რომელშიც ყველა ცვლილებაა ჩასმული. მასტერს შეუძლია ამ ჟურნალების გაგზავნა ქსელში. ეს ყველაფერი ძალიან მარტივია და, როგორც ჩანს, მუშაობს.
რას აკეთებს მონა? უმჯობესია არ გაუგზავნოთ ცვლილებები მონას, რადგან შეიძლება რაღაც გაუგებარში მოხვდეთ. მონას ცოტა მეტი სამუშაო აქვს. გარდა ერთი დამატებითი ჟურნალის შენახვისა და მოთხოვნისამებრ გაგზავნის, ასევე არის თემა, რომელიც მიდის დისტანციურ ოსტატთან, შესაძლოა ერთზე მეტსაც კი, და იქიდან ჩამოტვირთავს ბინარულ ჟურნალს დისტანციური ოსტატების "განსხვავებული ჟურნალის ჩამოტვირთვა" ორაზროვანია, ერთის მხრივ, ეს არ არის ცუდი, მაგრამ, მეორეს მხრივ, არის მყისიერი შეუსაბამობა, თქვენ არ შეგიძლიათ უბრალოდ ფიზიკურად დააკოპიროთ ფაილები სერვერზე. ის შეიცავს თქვენს საკუთარ პოზიციებს, ლოკალურად ვთრევთ მათ ქსელის გასწვრივ, ვდებთ ცალკეულ ჟურნალში, გაშვებულია სხვა ცალკეული თემა და ცდილობს ამ ლოკალური ჟურნალების დაკვრას, ჩემი აზრით, ყველაზე ჯოჯოხეთური რამ არის ის, რომ 5.6 ვერსიამდე. ჟურნალში კონკრეტული ტრანზაქციის იდენტიფიცირება მოხდა ფაილის სახელით და პოზიციით მასტერზე.
აქ არის ჩაწერის გზა, რომელსაც უბრალო ჩანართი გადის რეპლიკაციის გარეშე:

პროგრამა დაკავშირებულია სერვერთან, ჩადეთ იგი ცხრილში და დატოვეთ.
რეპლიკაციასთან ერთად, არსებობს რამდენიმე დამატებითი ნაბიჯი:

ჩაწერის აპლიკაცია ანალოგიურად მიდის მასტერზე, მაგრამ გარდა ამისა, ეს მონაცემები ამა თუ იმ ფორმით მთავრდება ბინარულ ჟურნალში, შემდეგ იტვირთება ქსელში სარელეო ჟურნალში, შემდეგ სარელეო ჟურნალიდან თანდათან ხელახლა ითამაშება. (თუ ჩვენ გაგვიმართლა და მონა არ ჩამორჩება, მაშინვე ხელახლა ითამაშებენ) მონაზე მაგიდაზე, რის შემდეგაც ყველაფერი ხელმისაწვდომია მკითხველში.
ზუსტად რა მთავრდება ბინარულ ჟურნალში, დამოკიდებულია SBR/RBR/შერეულ პარამეტრებზე. საიდან იზრდება ეს ყველაფერი? წარმოვიდგინოთ საკუთარი თავი, როგორც მონაცემთა ბაზა. ჩვენ მივიღეთ მარტივი მოთხოვნა „განაახლეთ ერთი კონკრეტული ჩანაწერი“ – განაახლეთ მომხმარებლები SET x=123 WHERE id=456
რა დავწერო ბინარულ ჟურნალში? პრინციპში, ყველაფერი ერთი და იგივეა, ნამდვილად. ჩვენ შეგვიძლია ჩამოვწეროთ მოკლე მოთხოვნა, ან (და მან განაახლა ერთი ჩანაწერი) ჩვენ შეგვიძლია ჩავწეროთ ცვლილება როგორმე ამა თუ იმ ფორმატში.
სხვა სიტუაცია. წარმოვიდგინოთ, რომ ჩვენ მივიღეთ იგივე მოთხოვნა, რომელიც თავისთავად მცირეა, მაგრამ ცვლის ბევრ მონაცემს - განაახლეთ მომხმარებლები SET ბონუსი=ბონუსი+100
არსებობს მხოლოდ ერთი ეფექტური ვარიანტი - თავად დაწეროთ მოთხოვნა, რადგან მოთხოვნა არის ზუსტად 32 ბაიტი და მას შეუძლია განაახლოს ჩანაწერების თვითნებური რაოდენობა - 1000, 100,000, 1,000,000, რამდენიც გინდათ... არაეფექტურია დაწერა. შეცვალა ჩანაწერები ჟურნალში.
რა მოხდება, თუ ჟურნალში ჩავსვამთ ასეთ მარტივ მოთხოვნას: „მოდით გამორთოთ ყველა მომხმარებელი, ვინც დიდი ხანია შესული არ არის“ – UPDATE users SET disabled=1 WHERE last_login
მოულოდნელად საშინელება იწყება. პრობლემა ის არის, რომ თუ თავად მოთხოვნა იდეალურად განმეორდება, მაშინ, პირველ რიგში, დრო არასოდეს არის სინქრონული ორ კვანძს შორის, გარდა ამისა, იმის გამო, რომ ჩაწერის გზა ძალიან გრძელია, განმეორების დროს ეს "NOW" განსხვავდებიან. რეპლიკა მოულოდნელად შორდება მასტერს და ყველა შემდგომი ცვლილება, ფორმალურად რომ ვთქვათ, აღარ არის უსაფრთხო და შეიძლება გამოიწვიოს რაიმე.
ზოგადად რომ ვთქვათ, ასეთი მოთხოვნებისთვის, მიუხედავად შეცვლილი მონაცემების რაოდენობისა, იდეალურ შემთხვევაში, საჭირო იქნებოდა თავად ხაზების კოპირება. ამ კონკრეტულ შემთხვევაში, თქვენ არ შეგიძლიათ თავად დააკოპიროთ ხაზები, მაგრამ დააფიქსიროთ მუდმივი და ჩაწეროთ ჟურნალში არა "NOW", არამედ კონკრეტული დროის ანაბეჭდი, რომელიც გამოიყენა მასტერმა რეპლიკაციის დროს.

სახალისო ფაქტები, რომლებსაც შემთხვევით გაიგებთ რეპლიკაციის ჯუნგლებში ჩაძირვისას. უფრო მეტიც, შეგიძლიათ არაღრმა ჩაყვინთვა - მაშინვე წააწყდებით მათ. შემთხვევითი თანმიმდევრობით ისინი არიან:
- ბატონი მრავალძაფია, მონა კი არა. გასაგებია, რომ თუ ოსტატი ტვირთს ოთხ ბირთვში ასხამს, მონას არ აქვს დრო, რომ ეს დატვირთვა ერთ ბირთვში გადაიტანოს. ეს ყველაფერი საკმაოდ ცუდია;
- Slave-ის მდგომარეობა განისაზღვრება მთავარ ფაილში პოზიციის დასახელებით. დაფიქრდით - კლასტერში ერთი კვანძის მდგომარეობა განისაზღვრება ფაილის სახელით და ამ ფაილის პოზიციით კლასტერის სხვა კვანძზე, რომლითაც ყველაფერი შეიძლება მოხდეს რაიმე მიზეზით!
- "გადარჩენა" RBR. გამოდის, რომ ნაგულისხმევად იქ იწერება სრული სტრიქონის წინ/შემდეგ სურათები, ე.ი. ჩვენ შევცვალეთ ერთი სვეტი ხუთ კილობაიტიან სტრიქონში, უი! – 10 კბაიტი ტრაფიკი და 20-40 ბაიტი ზედნადები ამ ხაზისთვის, მაშინ უი! - არის ასეთი თამამი ხაზი წინა ვერსიიდან, ოჰ! – ამის შემდეგ არის ვერსია ახალი მნიშვნელობებით. ადმინისტრატორები ყვირიან ერთხმად! თუმცა, ეს უბრალოდ გასაოცარია ზოგიერთი გაუკუღმართებული აპლიკაციის თვალსაზრისით, მაგალითად, გარე წამკითხველები, რომლებიც ცდილობენ დაუკავშირდნენ MySQL სერვერს, ამოიღონ მონაცემები მისგან და გააკეთონ რაიმე, მაგალითად, ჩაატარონ იგი სრულად- ტექსტის ინდექსი. რაც არ უნდა ცუდი იყოს ეს მონაცემთა ბაზის ადმინისტრაციის თვალსაზრისით, რომლის დროსაც ერთი ცვლილება სამ ბაიტზე წარმოქმნის 10 KB ტრაფიკს ხრახნიზე, შემდეგ კი 10 KB ქსელის ტრაფიკს თითოეული სლავისთვის, ეს ისეთივე კარგია ნებისმიერი სისტემისთვის. როგორც სრული ტექსტის ძიება, როგორიცაა Sphinx, რომელიც არ არის მონაცემთა ლოკალური ასლი და არ არსებობს MySQL ნულიდან განხორციელების სურვილი. MySQL 5.6-ში მათ გააცნობიერეს და შექმნეს binlog_row_image (მაგრამ ნაგულისხმევად სრული, არა მინიმალური ან noblob).
მოკლედ, ყველაფერი ჭკვიანურად არ არის მოწყობილი - ჯოხი, თოკი, ერთი მორი, მეორე მორი. და ამ ჟურნალშიც კი, "ბავშვობის" დაავადებები საკმაოდ სასაცილოა:

ადამიანისთვის, რომელიც ორი დღეა რეპლიკაციას იყენებს, ეს ყველაფერი საშინელი და რთულია. მაგრამ, იმის ცოდნა, თუ რამდენად მარტივია ეს, პრინციპში, გასაგებია, თუ როგორ უნდა იცხოვრო მასთან:
- პირველ რიგში, ჩვენ არ გვჯერა დეფოლტის;
- ჩვენ ყურადღებით ვათვალიერებთ პარამეტრებს, ვფიქრობთ რა გვინდა - SBR, RBR და ა.შ.
და ჯობია დაუყონებლივ დააყენოთ, რათა მოგვიანებით არ დაგჭირდეთ უცნაური ფარშის დალაგება.
სიტუაციაში "ლოგი დაზიანებულია, პოზიცია განსხვავებულია, არ არის ცნობილი რა ხდება", არის გარკვეული ინსტრუმენტარიუმი - ჩვენ ვუყურებთ მოვლენებს, ვცდილობთ გავიგოთ, რომელმა ტრანზაქციამ უკვე გაიარა, რომელი არა, შესაძლებელია მთელი ნივთის შენახვა ან აღდგენა და ა.შ. თუ GTID „თუ თქვენ მოახერხეთ მისი ჩართვა წინასწარ, მაშინ ცხოვრება გაგიადვილდებათ.
კიდევ ერთი წერტილი რეპლიკაციაზე დაკვირვებისას. საინტერესოა იმის დანახვა, თუ როგორ პროვოცირებას უწევს შიდა დახრილი სტრუქტურა არა მხოლოდ კონკურენციას, არამედ დამატებითი პროდუქტების შექმნას. "ჯადოსნური" ვოლფრამის რეპლიკატორი, მათი თქმით, კარგად წყვეტს პრობლემას, სახელწოდებით "ერთი ძაფის მონა ცუდია", და რომ არა თანდაყოლილი სირთულეები, არ იქნებოდა დამატებითი პროდუქტი, რომელიც საშუალებას მოგცემთ გამოიყენოთ ეს მექანიზმი, გადაიტანოთ მონაცემები სხვა სისტემები, ერთი მხრივ, და ამავდროულად წყვეტს არსებულ სისტემაში ჩაშენებულ მთელ რიგ პრობლემებს, მეორე მხრივ.
როგორც ყოველთვის, რჩევის მიცემა შეუძლებელია. ზოგს ეხმარება, სხვები ბევრს აფურთხებენ. მაგრამ ისინი ამბობენ, რომ არის სიტუაციები, როდესაც ვოლფრამი კარგად უმკლავდება გარდაუვალ ერთძაფის ჩამორჩენას. დარწმუნებული ვარ, არსებობს სხვა საინტერესო ხრიკები, მაგრამ შიდა ერთი ძაფიანი მონა რთულია.
რა უნდა გააკეთოთ, თუ რაიმე მიზეზით იყენებდით ასლებს, როგორც სარეზერვო? ვფიქრობ, თავი კედელს უნდა მიარტყა, რადგან რეპლიკა და სარეზერვო ორი განსხვავებული რამ არის. თუმცა, თუ თქვენ ხართ კრეატიული ბიჭები და იყენებთ საკმაოდ ახალ ვერსიას, დაგვიანებული რეპლიკაცია გიშველის, ერთი მხრივ, მაგრამ, მეორე მხრივ, თუ არ გააკეთებთ სრულ სარეზერვო ასლებს, მაინც არაფერი გიშველის.
შემდეგი არის შემოქმედების კიდევ ერთი ელემენტი. ძნელი წარმოსადგენია სიტუაცია, როდესაც მასტერმა შეავსო მთელი 10 PB ღრუბლოვანი დისკი ჟურნალებით ან შეავსო მთელი ქსელი ამ ჟურნალების გაგზავნით, მაშინ როცა ჩვენ არ გვჭირდება ამ განახლებების 90%, რადგან ჩვენ დაინტერესებული ვართ რეპლიკაციით. მაგალითად, ერთი ცხრილი ხედზე ან ერთი მონაცემთა ბაზა ხედზე, და ნაგულისხმევად ყველაფერი იღვრება ბინარულ ჟურნალში - ყველა ცვლილება ყველა მონაცემთა ბაზაში, ყველა ცხრილში, ყველაფერში. გამოსავალი კვლავ აოცებს თავისი კრეატიულობით. ერთის მხრივ, არის ოთხი პარამეტრი - (binlog|replicate)_(do|ignore)_db, რომელიც საშუალებას გაძლევთ გაფილტროთ მასტერზე, რა ჩაიწერება ჟურნალში და რა იქნება იგნორირებული. მონაზე, შესაბამისად, იგივეს გაკეთების საშუალებას გაძლევთ. იმათ. მასტერზე შეგვიძლია გავფილტროთ ის, რაც შედის ბინარულ ჟურნალში - ამ ძაბრში, რომელიც შემდეგ ერწყმის ქსელს და სლავზე, შესაბამისად, შეგვიძლია შემომავალი ფილტრი დავაყენოთ ქსელიდან მოსულზე. ან ჩაწერეთ მონაცემების მხოლოდ ნაწილი დისკზე, შემდეგ კი ხელახლა დაუკრათ მონაცემების მხოლოდ ნაწილი მონაზე. უცებ, ამ უბრალო ამბავშიც კი საშინელება დგება, რადგან კომბინაცია - ვიყენებთ ერთ მონაცემთა ბაზას და ვაახლებთ ცხრილს სხვა მონაცემთა ბაზაში საინტერესო სინტაქსის გამოყენებით - ის რაღაცნაირად იქცევა... და ზუსტად როგორ მოიქცევა უცნობია, რადგან სხვადასხვა ფილტრები ამოქმედდება სხვადასხვა დროს.
არ არის ჩაშენებული ლამაზი რამ, რომელსაც ჰქვია "ოსტატის ხელახალი არჩევა, თუ ის მოულოდნელად მოკვდება" თქვენ უნდა აწიოთ ის თქვენი ხელებით. კლასტერების მართვის ინსტრუმენტების ნაკლებობა - ეს, ჩემი აზრით, კარგია - იწვევს კონკურენციას, იძლევა დამატებითი პროდუქტების შექმნას. სინამდვილეში, თუ ძალიან მაგარი მასტერ-მასტერ რეპლიკაცია მშვენივრად მუშაობდა ჩვეულებრივ MySQL-ში, ან მინიმუმ ავტომატური აღდგენა წარუმატებლობის შემდეგ, მაშინ რატომ იქნებოდა საჭირო ყველა Galera, Percona/MariaDB Cluster და ა.შ.?
კიდევ რამდენიმე ხრიკი. საინტერესო განხორციელებაა რეპლიკაცია, რომელიც ისეთივე მარტივია, როგორც ჯოხი და თოკი, ყოველგვარი შემოწმების გარეშე, ერთის მხრივ, და ყოველგვარი ხელსაწყოების გარეშე, რათა უფრო სასიამოვნო გახდეს რეპლიკაციური მონას კლასტერის მართვა, მეორე მხრივ. ეს ცუდია. მაგრამ თქვენ შეგიძლიათ ხელით მოაწყოთ იქიდან ისეთი საინტერესო კონფიგურაციები, რომ ყველა, ვინც მოგვიანებით მოვა და გამოგლიჯავთ, შეკრთება.
კონფიგურაცია No1. Master-Master "მუხლზე" MySQL სტილში კეთდება ასე:

რა საშინელებაა, რამდენი იდიოტია მსოფლიოში! Google „Master-master MySQL replication“ - ყოველი მეორე ბმული ასეთია. ჯოჯოხეთი და ჰოლოკოსტი.
ფოკუსი No2 - catch-all slave - უფრო სასიამოვნოა. არ არსებობს ზედმეტი შემოწმებები - რა დაფრინავს ვისგან, ვინ იღებს და რა უნდა გააკეთოს. ამის გამო, შეგიძლიათ გააკეთოთ სასაცილო რაღაცეები, როგორიცაა მონა, რომელზედაც ზუსტად არის გაერთიანებული სერვერების მონაცემების ნაწილი, ან ყველა სერვერის ყველა მონაცემი ზუსტად არის გაერთიანებული - სერვერი ყველა სარეზერვო ასლით. მაგრამ, ვიმეორებ, არის რეპლიკაცია, ე.ი. არსებობს გარკვეული ძირითადი ინსტრუმენტი, რომელიც აკოპირებს A ცხრილს B-ის ნაცვლად და ეს არის ის.
და ბოლოს, ხრიკი No3 - ჩვენ ვცვლით ყველაფერს. გავიხსენოთ, რომ რეპლიკაცია ცხოვრობს ლოგიკურ დონეზე, რაც არანაირად არ არის დაკავშირებული ფიზიკურ შენახვის დონესთან. ამის გამო, თქვენ შეგიძლიათ შექმნათ ძალიან საინტერესო უცნაური რამ. თქვენ შეგიძლიათ შეცვალოთ ძრავა „დაფრენისას“ გაურკვეველი მიზნებისთვის - აქ არის ნამდვილი ამბავი, რომ, მათი თქმით, InnoDB მონაცემთა ბაზებიდან MyISAM ცხრილებზე რეპლიკაცია უბრალოდ იმისთვისაა, რომ სრული ტექსტის ძებნა მაინც რაიმენაირად იმუშაოს. არსებობს კრეატიული ხრიკი სახელწოდებით "სქემის მოდიფიკაცია რეპლიკაციის გზით". უარს ვამბობ იმის გაგებაზე, თუ რა არის ცხიმი, მაგრამ არის ასეთი ხრიკები. არსებობს მოქმედების მკაფიო და საინტერესო რეჟიმი, სახელწოდებით „პარანოიდული ვერსიის განახლება რეპლიკაციის გზით“.
მოხსენების დროს გავიგეთ:

მიუხედავად ამისა, თქვენ შეგიძლიათ იცხოვროთ ამ ჯოჯოხეთთან, თუ დაახლოებით მაინც გესმით, როგორ მუშაობს იგი.
მთავარი მესიჯი არის ის, რომ:

2015 წელს, HighLoad++ Junior კონფერენციაზე, ანდრეი აქსენოვმა წაიკითხა თავისი მოხსენების ახალი ვერსია რეპლიკაციის მოწყობილობის შესახებ MySQL-ში. ჩვენს ბლოგზეც გავშიფრეთ.
რეპლიკაცია არის ობიექტის მრავალი ასლის შინაარსის სინქრონიზაციის მექანიზმი. ეს პროცესი ეხება მონაცემთა ერთი წყაროდან ბევრ სხვაზე გადაწერას და პირიქით.
აღნიშვნები:
- master - მთავარი სერვერი, რომლის მონაცემების დუბლირებაა საჭირო;
- რეპლიკა - გარემონტებული სერვერი, რომელიც ინახავს ძირითადი მონაცემების ასლს
MySQL-ში რეპლიკაციის დასაყენებლად, თქვენ უნდა დაიცვათ ქვემოთ აღწერილი მოქმედებების თანმიმდევრობა, მაგრამ ეს არ არის დოგმატი და პარამეტრები შეიძლება შეიცვალოს გარემოებების მიხედვით.
მთავარ სერვერზე შეცვალეთ my.cnf ფაილი და დაამატეთ შემდეგი ხაზები mysqld განყოფილებაში:
Server-id = log-bin = mysql-bin log-bin-index = mysql-bin.index log-error = mysql-bin.err relay-log = relay-bin relay-log-info-file = relay-bin. info relay-log-index = relay-bin.index expire_logs_days=7 binlog-do-db =
- - უნიკალური MySQL სერვერის იდენტიფიკატორი, ნომერი 2 დიაპაზონში (0-31)
- - მონაცემთა ბაზის სახელი, რომლის შესახებაც ინფორმაცია ჩაიწერება ორობითი ჟურნალში, თუ არსებობს რამდენიმე მონაცემთა ბაზა, მაშინ თითოეული მოითხოვს ცალკე ხაზს binlog_do_db პარამეტრით
Slave-ზე დაარედაქტირეთ my.cnf ფაილი და დაამატეთ შემდეგი ხაზები mysqld განყოფილებაში:
Server-id = master-host = master master-user = replication master-password = პაროლი master-port = 3306 relay-log = relay-bin relay-log-info-file = relay-log.info relay-log-index = relay-log.index replicate-do-db =
მთავარ სერვერზე დაამატეთ რეპლიკაციის მომხმარებელი მონაცემთა რეპლიკაციის უფლებებით:
მინიჭება REPLICATION SLAVE ON *.* TO "replication"@"replica" იდენტიფიცირებული "პაროლით"
მოდით დავბლოკოთ რეპლიკაციური მონაცემთა ბაზები მთავარ სერვერზე, რათა შეცვალონ მონაცემები, პროგრამულად ან MySQL ფუნქციონალობის გამოყენებით:
Mysql@master> FLUSH TABLES WITH READ LOCK; mysql@master> SET GLOBAL read_only = ON;
განბლოკვისთვის გამოიყენეთ ბრძანება:
Mysql@master> SET GLOBAL read_only = OFF;
მოდით შევქმნათ ყველა მონაცემთა ბაზის სარეზერვო ასლი მთავარ სერვერზე (ან ის, რაც ჩვენ გვჭირდება):
Root@master# tar -czf mysqldir.tar.gz /var/lib/mysql/
ან გამოიყენეთ mysqldump უტილიტა:
Root@master# mysqldump -u root -p --lock-all-tables > dbdump.sql
მოდით გავაჩეროთ ორივე სერვერი (ზოგიერთ შემთხვევაში ამის გარეშეც შეგიძლიათ):
Root@master# mysqlamdin -u root -p გამორთვა root@replica# mysqlamdin -u root -p გამორთვა
მოდით აღვადგინოთ ტირაჟირებული მონაცემთა ბაზები მონა სერვერზე დირექტორიის კოპირებით. რეპლიკაციის დაწყებამდე მონაცემთა ბაზები უნდა იყოს იდენტური:
Root@replica# cd /var/lib/mysql root@replica# tar -xzf mysqldir.tar.gz
ან mysql ფუნქციონალობაზე, მაშინ არ იყო საჭირო mysql-ის შეჩერება მონა სერვერზე:
Root@replica# mysql -u root -p< dbdump.sql
მოდით გავუშვათ mysql მთავარ სერვერზე (და შემდეგ slave სერვერზე, საჭიროების შემთხვევაში):
Root@master# /etc/init.d/mysql დაწყება root@replica# /etc/init.d/mysql დაწყება
მოდით შევამოწმოთ ძირითადი და slave სერვერების მუშაობა:
Mysql@replica> start slave; mysql@replica> SLAVE STATUS-ის ჩვენება\G mysql@master> აჩვენე MASTER STATUS\G
Slave სერვერზე, შეამოწმეთ ჟურნალები master.info ფაილში, ის უნდა შეიცავდეს მოთხოვნას მონაცემთა ბაზაში მონაცემების შეცვლის შესახებ. ასე რომ, ეს ორობითი ფაილი ჯერ უნდა გადაკეთდეს ტექსტურ ფორმატში:
Root@replica# mysqlbinlog master.info > master_info.sql
თუ შეცდომები მოხდა, შეგიძლიათ გამოიყენოთ ბრძანებები:
Mysql@replica> stop slave; mysql@replica> RESET SLAVE; mysql@master> RESET MASTER;
და გაიმეორეთ ყველა ნაბიჯი, დაწყებული მონაცემთა ბაზების დაბლოკვით.
რეპლიკაციის სერვერების დასამატებლად შეგიძლიათ გამოიყენოთ შემდეგი სინტაქსი:
Mysql@replica> SLAVE STATUS-ის ჩვენება\G mysql@master> SHOW MASTER STATUS\G mysql@replica-2> CHANGE MASTER TO MASTER_HOST = "master", MASTER_USER =რეპლიკაცია, MASTER_PASSWORD = "LE-LOG_sword", bin.000004 ", MASTER_LOG_POS = 155; mysql@replica-2> START SLAVE;
სტატუსებიდან მიღებული ინფორმაცია აჩვენებს მიმდინარე ჟურნალის ფაილის პოზიციას და სახელს.
ასინქრონული რეპლიკაციით, ერთი რეპლიკიდან განახლება გავრცელდება სხვებზე გარკვეული დროის შემდეგ, ვიდრე იმავე ტრანზაქციაში. ამრიგად, ასინქრონული რეპლიკაცია იწვევს შეყოვნებას, ან ლოდინის დროს, რომლის დროსაც ცალკეული რეპლიკა შეიძლება არ იყოს ეფექტური იდენტური. მაგრამ ამ ტიპის რეპლიკაციას ასევე აქვს დადებითი ასპექტები: მთავარ სერვერს არ სჭირდება მონაცემთა სინქრონიზაცია, თქვენ შეგიძლიათ დაბლოკოთ მონაცემთა ბაზა (მაგალითად, სარეზერვო ასლის შესაქმნელად) მომხმარებელთა პრობლემების გარეშე.
გამოყენებული წყაროების სია
- Habrahabr.ru - MySQL-ში რეპლიკაციის საფუძვლები (http://habrahabr.ru/blogs/mysql/56702/)
- ვიკიპედია (http://ru.wikipedia.org/wiki/Replication_(გამოთვლითი_ტექნოლოგია))
საიტიდან ნებისმიერი მასალის მთლიანად ან ნაწილობრივ გამოყენებისას, მკაფიოდ უნდა მიუთითოთ ბმული, როგორც წყარო.