Indexy v 1s dopytoch. Optimalizácia dopytu. Registrácia používateľov vo viacerých rolách, každá s RLS
Prečítajte si tiež
Pošlite mi tento článok na môj email
V tomto článku sa pozrieme na to, ako indexovať platy v 1C ZUP pre zamestnancov organizácie. Podľa článku 134 Zákonníka práce Ruskej federácie, v ktorom sa uvádza, že zamestnávateľ musí zamestnancom zvýšiť platy, pretože náklady na tovar a služby sa pravidelne zvyšujú. Ak je organizácia financovaná z rozpočtu, indexácia sa vykonáva aj v súlade so Zákonníkom práce Ruskej federácie, rôznymi zákonmi alebo kolektívnou zmluvou.
Pod indexáciou miezd treba v prvom rade rozumieť zvýšenie tarifných sadzieb - platov, a to ako pre celý podnik, tak aj pre jeho jednotlivé divízie či pobočky. Hodnota koeficientu sa v budúcnosti použije pri výpočte dovolenky, pracovných ciest, priemerného zárobku a iných prípadoch.
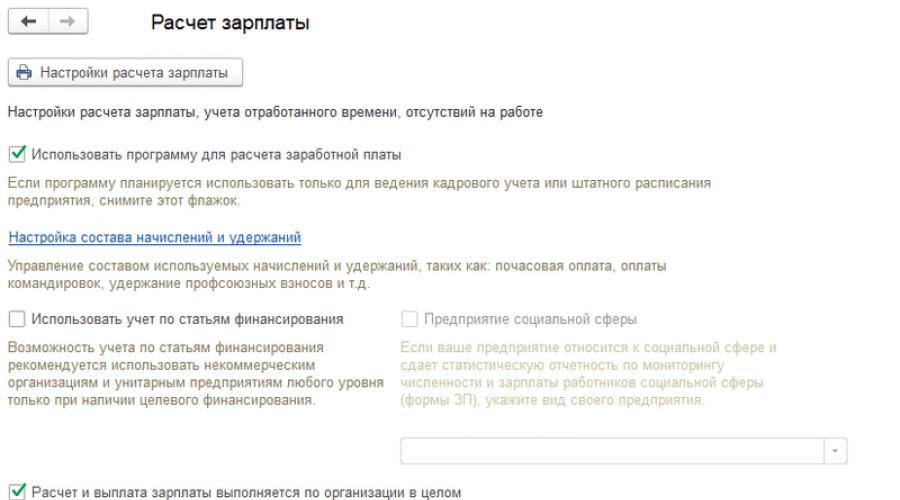
Ak chcete vykonať indexáciu miezd v 1C ZUP, musíte v programe vykonať niekoľko krokov. Prvá vec, ktorú musíte urobiť, je skontrolovať, či sú nastavené požadované nastavenia. V časti „Nastavenia“ vyberte položku „Výpočet miezd“. Vyžaduje sa začiarkavacie políčko označujúce, že príjmy sú indexované v databáze.

Mali by ste sa tiež uistiť, že sa uchovávajú personálne záznamy a udržiava sa história. Ak chcete skontrolovať dostupnosť týchto možností, musíte vybrať položku „HR“ a kliknúť na odkaz „Nastaviť tabuľku zamestnancov“.

Na indexovanie v programe, počnúc verziou 3.1.3, existuje špeciálny dokument „Zmena tabuľky zamestnancov“, ktorý sa nachádza v časti „Personál“. Vytvoríme nový dokument a vyplníme dátum, od ktorého budú zmeny a usporiadanie účinné. Na vyplnenie tabuľky. časti, kliknite na tlačidlo „Zmeniť“ a pridajte požadované jednotky rozvrhu.

Kliknutím na tlačidlo „Viac“ vpravo a výberom položky „Zobrazené indikátory“ môžete pomocou začiarkavacích políčok ovládať viditeľnosť indikátorov a zobraziť len tie, ktoré sú v dokumente požadované. Ďalej kliknite na tlačidlo „Vyplniť ukazovatele“ a v okne, ktoré sa otvorí, nastavte koeficient pre ukazovateľ „Mzda“ na 1,1.

Po potvrdení sa hodnoty v dokumente pre všetky riadky prepočítajú s prihliadnutím na tento koeficient. Kliknutím na odkaz „Podpisy“ v spodnej časti dokumentu môžete uviesť vedúceho organizácie a vedúceho personálneho oddelenia. V budúcnosti sa budú zobrazovať v tlačenej forme príkazu na zmenu harmonogramu, ktorý je možné vytlačiť pomocou tlačidla „Objednať zmeny“. Potom vykonáme dokument.
Ak máte otázky na tému Indexácia platov v 1C ZUP, opýtajte sa ich v komentároch pod článkom, naši špecialisti sa ich pokúsia zodpovedať.
Aby ste odzrkadlili skutočnosť zvýšenia miezd, musíte vytvoriť dokument „Zmena plánovaného časového rozlíšenia“, ktorý sa nachádza v časti „Mzdy“, položka „Zmena mzdy zamestnanca“. Keďže v našom príklade je uchovávaná história zmien v personálnej tabuľke, vyššie uvedený doklad je možné zadať z vytvoreného dokumentu „Zmena v personálnej tabuľke“ pomocou príslušného tlačidla.

Potom sa vytvorí hotový dokument. Upozorňujeme, že políčko „Považovať za indexáciu zárobkov“ musí byť začiarknuté.

Potom vykonáme dokument. Pri výplate miezd za nasledujúci mesiac sa mzda vypočíta s prihliadnutím na indexáciu.
Tím skúsených 1C programátorov:
Od 5 minút odozvy až po naliehavé úlohy, dokonca aj cez víkendy a sviatky.
30+ programátorov s až 20-ročnými skúsenosťami v 1C.
K dokončeným úlohám robíme videonávody.
Živá komunikácia prostredníctvom akýchkoľvek messengerov vhodných pre klienta
Sledovanie dokončenia vašich úloh prostredníctvom našej špeciálne vyvinutej aplikácie
Oficiálni partneri spoločnosti 1C od roku 2006.
Skúsenosti s úspešnou automatizáciou od malých firiem až po veľké korporácie.
99% klientov je spokojných s výsledkami
alebo
Prečo musí vývojár 1C „indexovať“ rozmery a podrobnosti?
- No, máte žiadosti! - databáza povedala a visela...
Krátka odpoveď na otázku v názve je, že to umožní rýchle spustenie dopytov a zníži negatívny vplyv zámkov na .
čo je index?

Optimalizácia umiestnenia indexu
Keď objem tabuliek neumožňuje „zapadnúť“ do RAM servera, rýchlosť diskového subsystému (I/O) je na prvom mieste. A tu môžete venovať pozornosť schopnosti umiestniť indexy do samostatných súborov umiestnených na rôznych pevných diskoch.

Podrobný popis akcií http://technet.microsoft.com/ru-ru/knižnica/pani175905.aspx
Použitie indexu z inej skupiny súborov zlepšuje výkon indexov bez klastrov vďaka súbežnosti medzi I/O procesmi a prácou na samotnom indexe.
Na určenie rozmerov je možné použiť vyššie uvedené spracovanie.
Vplyv indexov na zámky
Absencia potrebného indexu pre dotaz znamená iteráciu cez všetky záznamy v tabuľke, čo následne vedie k redundantným zámkom, t.j. nepotrebné záznamy sú zablokované. Navyše, čím dlhšie trvá dokončenie dotazu kvôli chýbajúcim indexom, tým dlhší bude čas držania zámku.
Ďalším dôvodom zámkov je malý počet záznamov v tabuľkách. V tomto ohľade SQL Server pri výbere plánu vykonávania dotazov nepoužíva indexy, ale prehľadáva celú tabuľku (Table Scan), čím blokuje celú tabuľku. Aby sa predišlo takémuto blokovaniu, je potrebné zvýšiť počet záznamov v tabuľkách na 1500-2000. V tomto prípade sa skenovanie tabuliek predraží a SQL Server začne používať indexy. Samozrejme, nie vždy sa to dá urobiť pri viacerých adresároch, ako sú „Organizácie“, „Sklady“, „Divízie“ atď. majú zvyčajne málo záznamov. V týchto prípadoch indexovanie nezlepší výkon.
Výkon indexu
Už v názve článku sme uviedli, že nás zaujíma vplyv indexov na výkon dotazov. Indexy sú teda najvhodnejšie pre nasledujúce typy úloh:
- Dopyty, ktoré špecifikujú „úzke“ kritériá vyhľadávania. Takéto dopyty musia čítať len malý počet riadkov, ktoré spĺňajú určité kritériá.
- Dotazy, ktoré špecifikujú rozsah hodnôt. Tieto dopyty tiež potrebujú prečítať malý počet riadkov.
- Vyhľadávanie, ktoré sa používa pri operáciách prepojenia. Stĺpce, ktoré sa často používajú ako kľúče väzby, sú skvelé pre indexy.
- Vyhľadávanie, pri ktorom sa údaje čítajú v určitom poradí. Ak sa má množina výsledkov triediť v klastrovanom indexovom poradí, nie je potrebné triedenie, pretože množina výsledkov je už vopred zoradená. Ak je napríklad vytvorený klastrovaný index v stĺpcoch priezvisko, krstné meno a aplikácia vyžaduje triedenie podľa priezviska a potom podľa mena, potom nie je potrebné pridávať klauzulu ORDER BY.
Pravda, pri všetkej užitočnosti indexov je tu jedno veľmi dôležité ALE – index musí byť „efektívne využívaný“ a musí umožňovať vyhľadávanie údajov s použitím menšieho počtu I/O operácií a množstva systémových prostriedkov. Naopak, nepoužívané (zriedkavo používané) indexy s väčšou pravdepodobnosťou zhoršujú výkon zápisu údajov (keďže každá operácia, ktorá upravuje údaje, musí aktualizovať aj indexové stránky) a vytvára nadbytočný databázový priestor.
Krytina(pre danú požiadavku) sa nazýva index, ktorý obsahuje všetky potrebné polia pre túto požiadavku. Ak je napríklad index vytvorený v stĺpcoch a, b a c a príkaz SELECT zisťuje údaje len z týchto stĺpcov, vyžaduje sa iba prístup k indexu.
Aby sme mohli určiť efektívnosť indexu, môžeme ho približne odhadnúť pomocou bezplatnej online služby, ktorá zobrazuje „plán vykonávania dotazov“ a použité indexy.
Správne používanie indexov môže zrýchliť dopyty nielen krát, ale stokrát, niekedy dokonca tisíckrát.
Tento druh zrýchlenia jednoducho nemožno dosiahnuť pomocou hardvéru. Preto je potrebné tejto téme venovať zvýšenú pozornosť.
Aby ste zrýchlili dotaz, často musíte vytvoriť svoj vlastný index a existuje niekoľko rôznych spôsobov, ako to urobiť.
Vo videonávodoch sa pozrieme na niekoľko spôsobov, ako vytvoriť index. Budeme uvažovať aj o situácii, keď index požadovaného zloženia nebude možné vytvoriť pomocou štandardných nástrojov platformy a bude potrebné ho vytvoriť v DBMS.
Nastavenie indexov pomocou štandardných nástrojov platformy
Lekcia ukazuje, aké indexy sa v skutočnosti vytvárajú pre objekty na úrovni DBMS.
Nie všetko v tejto téme je také samozrejmé, ako by sa na prvý pohľad mohlo zdať. Koniec koncov, pre množstvo objektov existujú funkcie vytvárania indexov.
V tomto videu sa pozrieme na všetky detaily.
Indexovanie s dodatočným objednaním
Video ukazuje rozdiel medzi možnosťou konštrukcie indexu Index od Index s prídavnými objednávanie.
Príklad ukazuje, aký druh indexu platforma vytvorí pri použití dodatočného objednávania.
Vytvorenie indexu pre dimenzie registra
Indexovanie prvej dimenzie registrov má niekoľko nuancií.
Video ukazuje, aké indexy sa vytvárajú pre merania registrov. Do úvahy sa berie aj situácia indexovania dimenzie prvého registra.
Podľa ustanovení článku 134 Zákonníka práce Ruskej federácie musia zamestnávatelia poskytnúť zamestnancom zvýšenie miezd v súvislosti s rastúcimi spotrebiteľskými cenami tovarov a služieb. Postup indexácie (berúc do úvahy stanovisko odborovej organizácie) je predpísaný v kolektívnej zmluve alebo v miestnom regulačnom akte organizácie. V článku odborníci 1C hovoria, ako indexovať tabuľku zamestnancov a aktuálne tarify zamestnaneckých taríf v 3. vydaní „1C: Platy a personálny manažment 8“ (s ďalším prepočítaním priemerného zárobku).
Indexovanie v „1C: Platy a personálny manažment 8“ (ed. 3) zvyčajne znamená dve úlohy:
- indexácia personálnej tabuľky - postupná zmena tarifných sadzieb v personálnej tabuľke (ak je použitá v programe);
- indexácia aktuálnych taríf zamestnaneckých tarifných sadzieb - zvýšenie tarifných sadzieb s ďalším prepočtom priemerného zárobku.
Indexácia tabuľky zamestnancov je možná, ak program „1C: Riadenie miezd a personálu 8“ vydanie 3 udržiava tabuľku zamestnancov s uloženou históriou (príznaky Udržiavať tabuľku zamestnancov a Udržiavať históriu zmien v tabuľke zamestnancov v menu Nastavenia - Personál záznamy - Vybrané je nastavenie pracovnej tabuľky).
Indexácia sa vykonáva v dokumente Zmena personálneho obsadenia. Výber indexovaných pozícií sa vykonáva pomocou tlačidla Zmeniť polohu. Kliknutím na tlačidlo Vyplniť ukazovatele označíte ukazovatele, ktoré sú označené v nastaveniach výpočtu mzdy ako určujúce zloženie celkovej tarifnej sadzby. Hodnoty týchto ukazovateľov je možné indexovať ich vynásobením indexačným koeficientom (obr. 1).
Ryža. 1. Indexáciu tabuľky obsadenia, pre ktorú sú uvedené tarifné skupiny a stupne (kategórie), musíte najskôr vykonať Schválenie tarifnej skupiny (menu Mzda - Schválenie tarifnej skupiny).
Ak chcete zmeny tarifných sadzieb pre tarifné kategórie premietnuť do tabuľky obsadenia v dokumente Schválenie tarifnej skupiny, kliknite na tlačidlo Zmeniť tabuľku obsadenia. V tomto prípade sa dokument Zmena personálnej tabuľky vytvorí automaticky. Indexácia personálnej tabuľky v programe nevedie automaticky k indexácii zárobkov zamestnancov a neovplyvňuje výpočet priemerného zárobku.
Indexácia aktuálnych taríf zamestnaneckých taríf
Počnúc verziou 3.1.3 v programe 1C: Platový a personálny manažment 8, vydanie 3, indexácia súčasných taríf zamestnaneckých tarifných sadzieb nie je jednoducho vyjadrená zvýšením tarifnej sadzby, ale môže byť kombinovaná so zmenami v iných tarifách. poplatkov, ktoré určujú zloženie celkovej tarifnej sadzby. V tomto prípade indexačný koeficient nie je určený, ale vypočíta sa ako pomer novej súhrnnej colnej sadzby k predchádzajúcej. Indexácia aktuálnych taríf zamestnaneckých tarifných sadzieb sa vykonáva pomocou dokumentu Zmena plánovaného časového rozlíšenia (menu Mzda - Zmena mzdy zamestnanca - tlačidlo Vytvoriť).
Aby bolo zvýšenie tarifných sadzieb systémom vnímané ako indexácia, teda uvádzanie zvyšujúceho sa koeficientu pre výpočet priemerného zárobku, v doklade Zmena plánovaného časového rozlíšenia by mal byť nastavený príznak Považovať za indexáciu zárobku (obr. 2).
 Ryža. 2. Indexácia zárobkov zamestnancov
Ryža. 2. Indexácia zárobkov zamestnancov Tento príznak je v dokumente dostupný, ak je povolená možnosť využitia mechanizmov indexácie miezd príznakom Indexujú sa zárobky zamestnancov (menu Nastavenia - Mzdy). Pomocou tlačidiel Výber alebo Vyplniť je potrebné vytvoriť zoznam zamestnancov, ktorých zárobky podliehajú indexácii. Ďalej kliknutím na tlačidlo Vyplniť ukazovatele v dokumente Zmena mzdy zamestnanca sa otvorí okno, kde môžete zadať pevné hodnoty (Pevná hodnota - pozri obrázok 2), alebo prepočítať predvyplnené pomocou matematických operácií (Pridať, Násobiť podľa) , s uvedením napríklad koeficientu, ktorým sa má násobiť Mzda, Hodinová sadzba alebo iný ukazovateľ, ktorý určuje zloženie celkovej tarifnej sadzby. Kliknutím na tlačidlo Príkaz na indexáciu zárobkov vygenerujete tlačený formulár príkazu na indexáciu zárobkov zamestnancov.
Ak podnik používa tarifné skupiny, potom dokument Zmena plánovaných poplatkov vytvoríte kliknutím na tlačidlo Zmeniť plánované poplatky v dokumente Schválenie tarifnej skupiny (menu Mzda - Schválenie tarifnej skupiny).
Tlačiť (Ctrl+P)
‘Tento materiál som skopíroval z disku ITS na zváženie a prípadnú diskusiu na tému optimalizácie dotazov https://its.1c.ru/db/metod8dev#content:5842:hdocOdporúčam všetkým programátorom 1C, aby si pozorne prečítali tento článok, pretože dopytovací jazyk je hlavným nástrojom platformy 1C. Článok poskytuje typické dôvody pre neoptimálny výkon dotazov, diagnostikovaný na úrovni konfiguračného kódu, a rozoberá techniky optimalizácie dotazov.
Hlavné dôvody pre neoptimálny výkon dotazov
1. Pripojí sa k poddotazom
Spojenia s poddotazmi by sa nemali používať. Len objekty metadát alebo dočasné tabuľky by mali byť navzájom prepojené. Ak dotaz používa spojenia s poddotazmi, potom by sa mal prepísať pomocou dočasné stoly.
Príklad suboptimálneho nebezpečného dotazu pomocou spojenia s poddotazom na pravej strane spojenia pomocou poddotazu:
VYBERTE SI . . . OD Dokument . Predaj tovaru a služieb LEVÉ SPOJENIE ( VYBERTE SI OD Register informácií . Limity KDE . . . SKUPINA BY . . . ) BY . . .
Ak chcete optimalizovať dotaz, mali by ste ho rozdeliť na niekoľko samostatných dotazov (podľa počtu poddotazov použitých v spojeniach). Odporúča sa umiestniť tieto požiadavky v jednej dávkovej požiadavke.
// Vytvorte dočasného správcu tabuliek manažér VT = Nový Správca rozvrhov ; Žiadosť = NovýŽiadosť ; Žiadosť . Správca rozvrhov = manažér VT ; // Text žiadosti o dávkuŽiadosť . Text = " // Vyplňte dočasnú tabuľku. Dopyt do registra limitov. | VYBERTE SI... | Limity PUT | FROM Information Register.Limits | KDE... | SKUPINA PODĽA... | INDEX BY...; // Vykonajte hlavný dotaz pomocou dočasnej tabuľky VYBERTE SI... Z dokladu o predaji tovaru a služieb LEFT JOIN Limity PODĽA...;" Pozor! V tomto príklade je veľmi dôležité indexovať vytvorenú dočasnú tabuľku. Všetky polia, ktoré sa používajú v podmienke spojenia, by mali byť špecifikované ako polia indexu.2. Pripojí sa k virtuálnym stolom
Ak dotaz používa pripojenie k virtuálnej tabuľke dotazovacieho jazyka 1C:Enterprise (napríklad „ RegisterAccumulations.Products.Remains() “) a dotaz funguje s neuspokojivým výkonom, odporúča sa vykonať volanie virtuálnej tabuľky do samostatného dotazu a uložiť výsledky do dočasnej tabuľky. To znamená, že by ste mali použiť rovnaké odporúčanie ako v prípade spojenia s poddotazom (pozri bod 1).
Faktom je, že virtuálne tabuľky používané v dopytovacom jazyku 1C:Enterprise možno pri preklade do SQL rozšíriť na poddotazy. Je to preto, že virtuálna tabuľka často (ale nie vždy) prijíma údaje z viacerých fyzických tabuliek DBMS. Ak použijete spojenie s virtuálnou tabuľkou, potom na úrovni SQL môže byť v niektorých prípadoch implementované ako spojenie s poddotazom. V tomto prípade môže optimalizátor DBMS zvoliť neoptimálny plán rovnakým spôsobom ako pri práci s poddotazom použitým explicitne v jazyku 1C:Enterprise.
3. Nezhoda medzi indexmi a podmienkami dotazu
Podmienky sú použité v nasledujúcich častiach žiadosti:
- VYBERTE... OD... ODKIAĽ<условие>
- PRIPOJENIE...POD<условие>
- VYBER Z<ВиртуальнаяТаблица>(, <условие>)
- MAJÚCE<условие>
Pre všetky tieto podmienky použité v dotaze musia existovať vhodné vhodné indexy na optimalizáciu výberu údajov podľa podmienky. Okrem toho je vhodný index taký, ktorý spĺňa nasledujúce požiadavky:
- Požiadavka 1. Index obsahuje všetky polia uvedené v podmienke;
- Požiadavka 2. Tieto polia sú na samom začiatku indexu;
- Požiadavka 3. Tieto polia sú v rade, to znamená, že polia, ktoré nie sú zahrnuté v požiadavke, nie sú medzi nimi „zaklinené“;
Hlavné indexy vytvorené 1C:Enterprise:
- indexovať podľa jedinečného identifikátora(odkaz) pre všetky entity objektu (adresáre, dokumenty atď.);
- registratúrny index(odkaz na dokument) pre tabuľky pohybov registra podriadené registrátorovi;
- index k obdobiu a hodnotám všetkých meraní pre súhrnné tabuľky akumulačných registrov;
- indexové obdobie, účet a hodnoty všetky merania pre konečné tabuľky účtovných registrov.
V prípadoch, keď automaticky vytvorené indexy nestačia, môžete v konfigurátore dodatočne indexovať podrobnosti objektu metadát. Malo by sa však pamätať na to, že vytvorenie indexu urýchľuje proces vyhľadávania informácií, ale môže trochu spomaliť proces ich zmeny používateľom (pridávanie, úprava a odstraňovanie) v režime spustenia podniku 1C. Indexy by sa preto mali vytvárať vedome a len vtedy, ak je presne známy dopyt, pre ktorý je takýto index potrebný. Nemali by ste vytvárať indexy „pre každý prípad“ alebo zámerne nadbytočné indexy. Nikdy by ste napríklad nemali dodatočne indexovať prvý rozmer registra, pretože hlavný index súčtovej tabuľky, ktorú platforma automaticky vytvorí, je vhodný na vyhľadávanie podľa hodnoty prvého rozmeru.
Konfigurácia popisuje register akumulácie Produkty v skladoch:
Obr 1. Príklad štruktúry evidencie hromadenia tovaru v skladoch
Platforma 1C:Enterprise automaticky vytvorí index pre bilančnú tabuľku tohto registra podľa obdobia a všetkých dimenzií v poradí, v akom sú uvedené v konfigurátore.
Pozrime sa na niekoľko príkladov dotazov a analyzujme, či sa dajú optimálne vykonať s touto dátovou štruktúrou.
Žiadosť 1
Žiadosť . Text = "VYBERTE si |OD , Nomenklatúra = &Nomenklatúra) AS Zostávajúce produkty v skladoch";V tomto prípade je porušená požiadavka 2 V podmienke nie je výber podľa prvého poľa indexu (Sklad). Takáto požiadavka nebude vykonaná optimálne. Na jeho vykonanie bude musieť server DBMS iterovať (skenovať) všetky záznamy v tabuľke. Čas vykonania tejto operácie priamo závisí od počtu záznamov v tabuľke zvyškov registra a môže byť veľmi veľký (a bude sa zvyšovať s rastúcim množstvom údajov).
Možnosti optimalizácie:
- Indexujte dimenziu „Nomenklatúra“.
- Umiestnite dimenziu „Nomenklatúra“ na prvé miesto v zozname dimenzií. Pri používaní tejto metódy buďte opatrní. V konfigurácii môžu byť ďalšie požiadavky, ktoré môže tento swap spomaliť.
Žiadosť 2
Žiadosť . Text = "VYBERTE si | TovarVSkladochZostatky.Sklad, | Nomenklatúra produktov v skladoch. | TovarVSkladochZostatky.Kvalita |OD | RegisterAccumulations.GoodsInWarehouses.Remains( | , | Kvalita = &Kvalita ;V tomto prípade je porušená požiadavka 3. Medzi dimenziami „Sklad“ a „Kvalita“ v štruktúre registra sa nachádza dimenzia „Nomenklatúra“, ktorá nie je uvedená v podmienke požiadavky. Tento dotaz tiež nebude možné vykonať optimálne. Po spustení DBMS vyhľadá prvé pole indexu, ale potom bude nútený naskenovať nejakú jeho časť. Skenovanie povedie k predĺženiu času vykonávania dotazu a zablokovaniu nadbytočných záznamov v tabuľke, teda k zníženiu celkovej priepustnosti systému.
Možnosti optimalizácie:
- Pridajte do požiadavky podmienku pre dimenziu „Nomenklatúra“.
- Odstráňte zo požiadavky podmienku pre dimenziu Kvalita
- Preneste „Nomenklatúru“ z meraní na detaily
- Vymeňte dimenzie „Nomenklatúra“ a „Kvalita“.
Žiadosť 3
Žiadosť . Text = "VYBERTE si | TovarVSkladochZostatky.Sklad, | Nomenklatúra produktov v skladoch. | TovarVSkladochZostatky.Kvalita, | ProductsIn WarehousesRemaining.QuantityRemaining |OD | RegisterAccumulations.GoodsInWarehouses.Remains( | , | Nomenklatúra = &Nomenklatúra | A Sklad = &Sklad) AKO TovarVSkladochZostávajúci";V tomto prípade nie sú porušené požiadavky na zhodu indexov a dotazov. Túto požiadavku vykoná DBMS optimálnym spôsobom. Upozorňujeme, že poradie podmienok v dotaze sa nemusí zhodovať s poradím polí v indexe. Toto nie je problém a DBMS to normálne spracuje.
4. Použitie logického ALEBO v podmienkach
4.1 Použitie logického OR v sekcii WHERE dotazu
V sekcii WHERE dotazu by ste nemali používať OR. To môže spôsobiť, že DBMS nebude môcť používať indexy tabuliek a bude vykonávať skenovanie, čo predĺži čas vykonania dotazu a pravdepodobnosť uzamknutia. Namiesto toho by ste mali rozdeliť jeden dotaz na niekoľko a výsledky skombinovať.
Napríklad žiadosť
VYBERTE produkt . názov OD Adresár . Produkty AKO Produkt KDE Článok = "001" ALEBO Kód dodávateľa = "002"
by mala byť nahradená žiadosťou
VYBERTE produkt . názov OD Adresár . Produkty AKO Produkt KDE Článok = "001" | KOMBINOVAŤ VŠETKO | VYBRAŤ produkt . názov OD Adresár . Produkty AKO Produkt KDE Článok = "002"
4.2. Registrácia používateľov vo viacerých rolách, každá s RLS
1 S RLS (Záznam úroveň Bezpečnosť) alebo obmedzenie práv na úrovni záznamu - ide o nastavenie práv užívateľa v systéme 1 S, ktorý umožňuje oddeliť práva pre používateľov v kontexte dynamicky sa meniacich údajov.
Ak konfigurácia popisuje niekoľko rolí s podmienkami RLS, potom by ste jednému používateľovi nemali priradiť viac ako jednu takúto rolu. Ak je jeden používateľ zaradený napríklad v dvoch rolách s RLS - účtovník a personalista, tak po vykonaní všetkých jeho požiadaviek sa podmienky oboch RLS pridajú k ich podmienkam pomocou logického OR. Týmto spôsobom, aj keď v pôvodnom dopyte nie je žiadna podmienka ALEBO, objaví sa tam, keď budú pridané podmienky RLS. Takáto požiadavka môže byť vykonaná aj neoptimálne - pomaly a s nadmernými zámkami.
Namiesto toho by ste mali vytvoriť „zmiešanú“ rolu – „účtovník-HR dôstojník“ a zaregistrovať jej RLS takým spôsobom, aby ste sa vyhli použitiu OR v podmienke, a zahrnúť používateľa do tejto jedinej roly.
4.3 Použitie OR v podmienkach pripojenia
Neodporúča sa používať logické OR v podmienkach pripojenia, to znamená v sekcii softvéru žiadosti. To môže viesť aj k výberu suboptimálneho plánu a pomalému výkonu dotazov. Neexistuje jednoduchý univerzálny spôsob, ako prepísať takýto dotaz bez použitia OR. Mali by ste analyzovať riešený problém a pokúsiť sa nájsť iný algoritmus na jeho riešenie.
5.Používanie poddotazov v stave spojenia
V podmienke spojenia by ste nemali používať poddotazy. To môže viesť k výraznému spomaleniu dopytu a (v niektorých prípadoch) k jeho úplnej nefunkčnosti na niektorých DBMS. Príklad dotazu pomocou poddotazu v podmienke spojenia:
Žiadosť . Text = "VYBERTE si |OD | Ceny Obdobie B (. | VYBERTE MAXIMUM(CenyPoslednýMesiac.Obdobie) | OD Registrovať Informácie Cena AKO CENY MINULÉHO MESIACA | KDE Ceny Minulý mesiac.Obdobie< НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | A ceny za posledný mesiac. Nomenklatúra = Zostávajúci tovar. Nomenklatúra |) | KDE sú zvyšné produkty.Sklad = &Sklad";
V tomto prípade sa poddotaz v podmienke spojenia použije na získanie, takpovediac, „výrezu najnovšieho“ na konci predchádzajúceho obdobia. Okrem toho môže byť pre každú nomenklatúru obdobie odlišné. Odporúča sa prepísať takýto dotaz pomocou dočasných tabuliek. Dá sa to urobiť napríklad takto:
Žiadosť . Text = " // Maximálne dátumy pre stanovenie cien v predchádzajúcom období pre tieto položky |VYBERTE | Zostávajúci tovar Nomenklatúra AS Nomenklatúra, | MAXIMÁLNE (Ceny.Obdobie) AS Obdobie |MIESTA DátumyPodľa nomenklatúr |OD | RegisterAccumulations.GoodsInWarehouses.Remainings(...) AS RemainingProducts | ĽAVÉ SPOJENIE RegistrovaťInformácie.Cena AKO Ceny | Ceny softvéru.Nomenklatúra = Zostávajúce produkty.Nomenklatúra A | Ceny. Obdobie< НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | GROUP BY Zostávajúce produkty.Nomenklatúra | WHERERemainingItems.Warehouse = &Warehouse; // Výber údajov podľa ceny za nájdené obdobie |VYBERTE | Dátumy Podľa nomenklatúr. Nomenklatúra AS Nomenklatúra, | Ceny. Cena AKO cena za posledný mesiac |OD DátumPodľa nomenklatúr | ĽAVÉ SPOJENIE RegistrovaťInformácie.Cena AKO Ceny | Ceny softvéru.Nomenklatúra = Zostávajúce produkty.Nomenklatúra A | Ceny.Obdobie = DátumyPodľaNomenklatúry.Obdobie " ;
6. Príjem údajov cez bodku z polí zloženého typu
Ak dotaz používa bodkovanú hodnotu z poľa typu komplexného odkazu, potom pri vykonávaní tohto dotazu sa vykoná spojenie so všetkými tabuľkami objektov zahrnutými v tomto komplexnom type. Výsledkom je, že SQL robí text dotazu extrémne zložitým a pri jeho vykonávaní môže optimalizátor DBMS vybrať suboptimálny plán. To môže viesť k vážnym problémom s výkonom a v niektorých prípadoch dokonca k zlyhaniu dotazu.
Neodporúča sa najmä pristupovať k údajom o registrátorovi (napríklad „ProduktyVSkladoch.Registrar.Dátum“) atď. V tomto prípade nezáleží na tom, v ktorej časti požiadavky použijete atribút prijatý cez bodku z poľa komplexného typu - v zozname vrátených polí, v podmienke atď. Vo všetkých prípadoch môže táto liečba viesť k problémom s výkonom.
- Vyhnite sa redundancii pri vytváraní polí zložených referenčných typov. Podľa potreby zadajte pre dané pole toľko možných typov. Nemali by ste zbytočne používať typy „akýkoľvek odkaz“ alebo „odkaz na akýkoľvek dokument“ atď. Namiesto toho by ste mali dôkladnejšie analyzovať svoju aplikačnú logiku a poliam priradiť presne tie možné typy odkazov, ktoré sú potrebné na vyriešenie problému.
- V prípade potreby obetujte kompaktné úložisko kvôli výkonu. Ak ste vo svojej požiadavke potrebovali hodnotu získanú prostredníctvom referencie, možno túto hodnotu možno uložiť priamo do tohto objektu. Ak napríklad pri práci s registrom potrebujete informácie o dátume registrátora, môžete v registri vytvoriť zodpovedajúce údaje a priradiť im hodnotu pri účtovaní dokladov. To povedie k duplicite informácií a určitému (miernemu) zvýšeniu ich objemu, ale môže to výrazne zlepšiť výkon a stabilitu požiadavky.
- V prípade potreby obetujte kompaktnosť a všestrannosť kódu pre výkon. Na splnenie konkrétnej požiadavky za daných podmienok spravidla nie sú potrebné všetky možné typy daného odkazu. V tomto prípade by ste mali obmedziť počet možných typov pomocou funkcie EXPRESS. Ak je tento dotaz univerzálny a používa sa v niekoľkých rôznych situáciách (kde môžu byť typy odkazov odlišné), potom môžete dotaz generovať dynamicky, pričom do funkcie EXPRESS nahradíte typ, ktorý je za týchto podmienok potrebný. Tým sa zväčší veľkosť zdrojového kódu a možno bude menej univerzálny, ale môže sa výrazne zlepšiť výkon a stabilita dotazu.
Príklad
Táto žiadosť využíva prístup k údajom o registrátorovi. Registrátor je pole zloženého typu, ktoré môže prijímať referenčné hodnoty jedného z 56 typov dokumentov.
Žiadosť . Text = "VYBERTE si | Sales.Registrar Number, | Sales.Registrar.Date, | Protistrana, | Predaj. Množstvo, | Predaj.Cost |OD | KDE...
Text SQL tohto dotazu bude obsahovať 56 ľavých spojení k tabuľkám dokumentov. To môže spôsobiť vážne problémy s výkonom pri spustení dotazu. Na vyriešenie tohto konkrétneho problému však nie je potrebné pripojiť sa ku všetkým 56 typom dokumentov. Podmienky požiadavky sú také, že pri jej realizácii sa vyberú len pohyby dokladov „Predaj tovaru a služieb“ a „Objednávky kupujúceho“. V tomto prípade môžeme dopyt výrazne urýchliť obmedzením počtu spojení pomocou funkcie EXPRESS().
Žiadosť . Text = "VYBERTE si | VOĽBA | POTOM VYJADRUJTE(Predaj.Doklad registra AS.Predaj tovaru a služieb).Číslo | POTOM EXPRESS(Predaj.Registrátor AKO doklad.Objednávka kupujúceho).Číslo | UKONČIŤ VÝBER AKO Číslo, | VOĽBA | KEĎ Predaje | POTOM VYJADRITE(Predaj.Registrátor AS doklad.Predaj tovaru a služieb).Dátum | KEĎ Sales.Registrar LINK Document.Buyer Order | POTOM EXPRESS(Predaj.Registrátor AKO doklad.Objednávka kupujúceho).Dátum | UKONČIŤ VÝBER AKO Dátum, | Protistrana, | Predaj. Množstvo, | Predaj.Cost |OD | RegisterAkumulácia.Predaj AKO Predaj | KDE | Predaj. Registračný LINK Dokument. Predaj tovaru a služieb | ALEBO Predaj. ODKAZ na dokument. Objednávky kupujúceho";
Tento dotaz je ťažkopádnejší a možno menej všeobecný (nebude fungovať správne v iných situáciách - kde sú možné iné hodnoty typu zapisovača). Po spustení sa však vygeneruje dotaz SQL, ktorý bude obsahovať iba dve pripojenia k tabuľkám dokumentov. Takáto požiadavka bude fungovať oveľa rýchlejšie a stabilnejšie ako žiadosť v pôvodnej podobe.
7. Filtrovanie virtuálnych tabuliek bez použitia parametrov
Pri používaní virtuálnych tabuliek v dotazoch by ste mali všetky podmienky súvisiace s touto virtuálnou tabuľkou odovzdať parametrom tabuľky. Neodporúča sa filtrovať virtuálne tabuľky pomocou podmienok v sekcii WHERE atď. Takýto dotaz vráti správny (z funkčného hľadiska) výsledok, ale pre DBMS bude oveľa ťažšie vybrať optimálny plán na jeho vykonanie. V niektorých prípadoch to môže viesť k chybám v optimalizátore DBMS a výraznému spomaleniu výkonu dotazov.
Napríklad nasledujúci dotaz používa sekciu WHERE dotazu na výber z virtuálnej tabuľky.
Žiadosť . Text = "VYBERTE si | Nomenklatúra |OD | RegisterAccumulations.GoodsInWarehouses.Remains() | KDE | Sklad = &Sklad";
Je možné, že v dôsledku vykonania tohto dotazu sa najskôr vyberú všetky záznamy virtuálnej tabuľky a potom sa z nich vyberie časť, ktorá vyhovuje zadanej podmienke. Najlepšie by bolo obmedziť počet záznamov získaných veľmi skoro v procese dotazovania. Na to je potrebné odovzdať podmienky parametrom virtuálnej tabuľky.
Žiadosť . Text = "VYBERTE si | Nomenklatúra |OD | RegisterAccumulations.GoodsInWarehouses.Remains(, Warehouse = &Warehouse)";